Karl Marx: Paris Manuscripts (1844)

This example uses Hellixia’s Knowledge Graph Generator to analyze Karl Marx’s Economic and Philosophical Manuscripts of 1844, also known as the Paris Manuscripts. Instead of processing the full manuscript in a single step, the workflow builds the graph incrementally by section, preserving local relationships while constructing a broader representation of the work.
The example focuses on Marx’s critique of political economy and his theory of alienation, and it demonstrates how Knowledge Graphs can be used for structured analysis of philosophical texts.
Understanding and Implementing Knowledge Graphs with Hellixia
What is a Knowledge Graph?
A Knowledge Graph is a structured representation of knowledge where information is organized as entities connected by relationships. Think of entities as the nodes in the graph - they represent concrete or abstract concepts, people, places, or ideas. These entities are connected by relationships (or edges) that describe how they interact or relate to each other.
In our implementation, these Knowledge Graphs are built upon Bayesian networks, making them Directed Acyclic Graphs (DAGs). This means that relationships between entities have specific directions, and no circular paths exist in the graph structure. While our implementation uses a noisy-OR specification for the conditional probability tables that define the strength of relationships, our focus remains on the qualitative aspects of these DAGs - the structural relationships and connections between concepts rather than their probabilistic properties.
For example, in analyzing philosophical texts, entities might include concepts like “labor,” “capital,” or “alienation,” while relationships might express connections like “influences,” “contradicts,” or “develops from.” This structure allows us to capture not just the concepts themselves, but how they interact and influence each other within the text.
Implementing Knowledge Graphs in Hellixia
Hellixia offers two distinct approaches to creating Knowledge Graphs. Let’s explore these methods and understand why we chose our specific approach for analyzing Marx’s Paris Manuscripts.
Method 1: Document Analysis Menu
The first approach utilizes Hellixia’s Document Analysis menu, where the Knowledge File is directly analyzed to extract both entities and relationships. In this method, each analysis of a Knowledge File results in the creation of a new network. This means that analyzing multiple parts of a text (such as different chapters) would generate separate, independent networks - one for each Knowledge Graph.
While this approach is straightforward for analyzing individual texts, attempting to create a Knowledge Graph for an entire book would require processing a single, large Knowledge File. Such an approach would likely result in an oversimplified analysis, as the complexity and volume of information would make it extremely challenging to capture the nuanced relationships and detailed concepts present in the complete work.
Method 2: Node-Based Analysis (Our Chosen Approach)
The second method employs a specific node as the target for Knowledge Graph analysis. This node-centric strategy allows for precision in focusing the analysis on various dimensions of the node:
Identifies the specific unit of analysis.
Provides additional descriptive information about the node.
Can be used to embed directly analyzable text, ideally suited for shorter documents.
Additionally, within the Knowledge Graph Generator wizard, the following option is available:
This option allows for the inclusion of a file containing text for analysis, particularly useful for more extensive documents.
This approach enhances the flexibility of the analysis, enabling the creation of detailed, interconnected Knowledge Graphs tailored to specific sections or themes within a single project.
When different Knowledge Graphs share common entities, they naturally integrate into an interconnected structure within the network. However, if there are no shared entities between the analyzed texts, the resulting Knowledge Graphs will exist independently within the same network structure. This unified network approach is particularly valuable for our chapter-by-chapter analysis of the “Paris Manuscripts,” as it allows us to:
Maintain separate but interconnected analyses for each chapter when shared concepts emerge.
Build a progressive, integrated understanding of Marx’s ideas through shared concepts.
Preserve the distinct context of each chapter while building toward a comprehensive view.
Building a Holistic Knowledge Graph of the Paris Manuscripts
Incremental Analysis Strategy
Our approach to creating a holistic Knowledge Graph of the Paris Manuscripts involves analyzing eleven distinct sections. Each section has been prepared as a separate PDF file to serve as a Knowledge File for our analysis, allowing precise control over the content being processed.
These eleven Knowledge Graphs will be generated within our unified BayesiaLab network:
First Manuscript (4 KGs)
Second Manuscript (1 KG)
Third Manuscript (6 KGs)
By generating these eleven Knowledge Graphs sequentially within the same network, we can:
Build up our understanding progressively.
Identify shared concepts and relationships across sections.
Observe how Marx develops and connects his ideas throughout the manuscripts.
Create naturally emerging clusters where concepts are interconnected.
Maintain distinct conceptual spaces where ideas are independent.
This methodical, section-by-section approach ensures we capture both the unique contributions of each section and the broader interconnections that form Marx’s comprehensive theoretical framework.
Creating Our First Knowledge Graph: Wages of Labour
Initial Setup and Configuration
We begin our incremental Knowledge Graph construction with the first section of the First Manuscript, Wages of Labour. Here’s the detailed process:
Create a new BayesiaLab graph and create a node named “Wages of Labour”.
Select the “Wages of Labour” node and navigate to Hellixia > Knowledge Graph Generator.
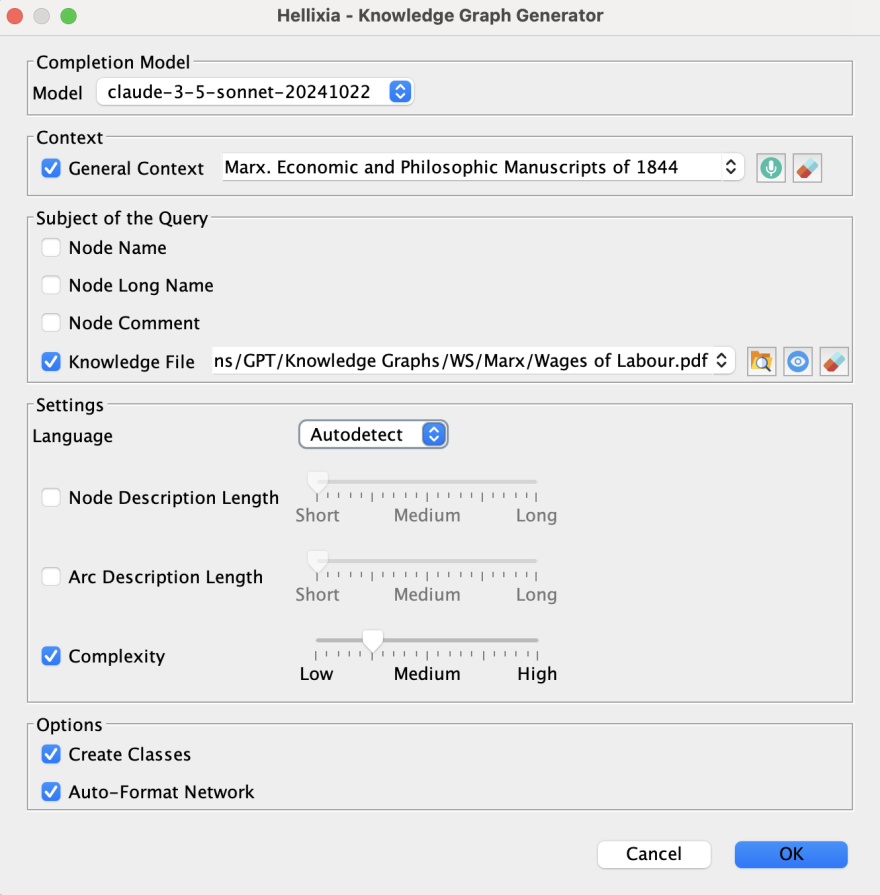
In the Knowledge Graph Generator wizard, set the following parameters:
Choose from the available Large Language Models, including OpenAI, Google, Meta, Mistral, and Anthropic models. For this analysis, select Claude Sonnet.
Set General Context to “Marx. Economic and Philosophic Manuscripts of 1844”. This provides essential background for the analysis.
In the Subject of the Query section, select only “Knowledge File”. Select “Wages of Labor.pdf” from the prepared files. The eye icon provides a preview feature to verify file content.

Set Language to “Autodetect” and choose an intermediate Complexity setting, between Low and Medium, to balance detail and clarity.
This configuration provides the foundation for our first Knowledge Graph. For our subsequent analyses, we will use the same template but with one key efficiency improvement: rather than creating a new node, we will rename the existing node to match each section being analyzed (e.g., “Profit of Capital”, “Rent of Land”, etc.). This naming approach is particularly important as it automatically creates a class named “Knowledge Graph of Node_Name” that contains all nodes generated in that section’s Knowledge Graph. This consistent naming convention ensures our incremental analysis remains organized and traceable, with each section’s concepts clearly associated with their source material.
Wages of Labor
Understanding the Knowledge Graph Structure
This Knowledge Graph visualizes key concepts and relationships detailed in the “Wages of Labor” section.
The graph illustrates three primary interrelated concepts: Capital, Wages, and Labor. Each node includes a detailed definition that captures Marx’s specific understanding of these terms. The relationships show the directional influence between concepts, though not necessarily causal influence.
Capital “empowers” the Capitalist, shown by a direct arrow. The Capitalist “exploits” the Worker and “determines” the Wages.
Three factors directly influence Wages:
The definition of Wages explicitly mentions the “struggle between capitalist and worker”.
The Industrial System “intensifies” the Division of Labor and “produces” Social Misery. Division of Labor leads to worker degradation.
The red arrow between Capital and Labor requires special attention:
Originally, the LLM suggested a relationship from Labor to Capital (“creates”).
This would have created a cycle in the graph, which is not allowed in the DAG structure.
The system automatically reversed the direction of the relationship, now from Capital to Labor.
This reversal is visually indicated by the red color of the arrow.
The relationship label needs to be manually adjusted from “creates” to “is created by” to maintain logical consistency with the reversed direction.
The color of each node is determined purely by its depth in the graph structure:
Nodes at depth 0, with no incoming relationships.
Nodes at intermediate depths.
Nodes at the deepest level.
The deepest level.
This color coding is a structural feature reflecting only the node’s position in the graph hierarchy, not its conceptual importance or influence
Each arc’s comment box contains a verb describing the relationship from Parent node to Child node. The comment boxes feature a dual-colored border that aids in relationship identification:
Top border color matches the parent node’s color.
Bottom border color matches the child node’s color.
This visual design becomes increasingly valuable as the Knowledge Graph grows more complex, helping to quickly trace relationships between nodes in dense networks.
Creating Our Second Knowledge Graph: Profit of Capital
Adapting Our Previous Node
Following our incremental approach, we’ll now build our second Knowledge Graph by:
Select the existing node Wages of Labour and rename it to Profit of Capital. This will automatically create a new class, “Knowledge Graph of Profit of Capital”, for the nodes and entities to be generated.
Using the same workflow as before, select the renamed node and navigate to Hellixia > Knowledge Graph Generator. Use the established configuration:
This approach maintains consistency in our analysis while building upon our existing network structure, allowing any shared concepts between sections to naturally integrate into our growing holistic Knowledge Graph.
Optimizing the Graph Visualization
After the Knowledge Graph Generator creates 6 new nodes in our network, we perform three key visualization optimizations:
Navigate to View > Graph Layout > Genetic Grid Layout and select Bottom-up Repartition. This organizes the nodes in a clear, hierarchical structure that optimizes the graph’s readability.
Navigate to View > Automatic Comment Layout. This automatically adjusts the position of arc comments, or relationship labels, to minimize overlaps and improve overall visibility.
Navigate to Edit > Edit Classes, select Generate a Predefined Class, choose “Depth” to create classes for each depth level in the graph, select all depth classes, and navigate to Colors > Associate Default Colors with Classes. This automatically assigns colors to nodes based on their structural depth in the graph.
These visualization steps ensure optimal readability as our network grows more complex with each additional Knowledge Graph.
After applying our visualization optimizations, we can observe that this Knowledge Graph introduced 6 new nodes to our network. Notably, unlike in our first Knowledge Graph of “Wages of Labour,” there are no red arcs in this new structure. This indicates that all relationships suggested by the LLM were naturally acyclic and did not require any arc reversals. As a result, all relationship labels (arc comments) maintain their original formulation, accurately representing the direct relationships identified by the LLM.
The Complete Knowledge Graph of Marx’s Paris Manuscripts
After applying our established workflow to all eleven sections of the Paris Manuscripts, we arrive at our final, comprehensive Knowledge Graph. Rather than detailing each incremental step, we’ll focus on analyzing the complete network that emerged from our systematic analysis.
It’s worth noting that this Knowledge Graph was initially generated using the French version of the manuscripts. We utilized Hellixia’s built-in translation feature (Hellixia > Translator) to convert the entire network into English, preserving both the node descriptions and relationship labels.
The Hellixia Translator is configured with the following settings:
The Context Setting plays a crucial role in achieving accurate, domain-specific translations. For example:
Travail Aliéné → *Alienated Labor*
Travail Aliéné → *Estranged Labor*
This demonstrates how the context helps the translator choose terminology consistent with established English translations of Marx’s work, rather than just literal translations.
This configuration ensures a comprehensive translation of all textual elements in our Knowledge Graph from French to English, maintaining consistency with the original philosophical context.
Visual Organization
In this holistic Knowledge Graph, we implemented a section-based color-coding scheme:
Each of the eleven sections from the manuscripts is assigned a distinct color.
The nodes are colored according to their source section.
For nodes that appear in multiple sections, or shared concepts, the color reflects the most recently created class, i.e., the last section where the concept appears.
Conclusion
The workflow presented in this article demonstrates a systematic approach to analyzing complex texts using Hellixia’s Knowledge Graph technology. While we demonstrate its application with Marx’s Paris Manuscripts, the same method can be applied beyond philosophical texts.
This versatile approach can be applied to any body of literature where understanding complex relationships between concepts is crucial:
Creating holistic representations of research fields by analyzing collections of academic papers.
Mapping relationships between system components and processes.
Understanding interconnections between market factors, strategies, and outcomes.
Capturing relationships between laws, precedents, and interpretations.
Building comprehensive concept maps across various subjects.
The key strengths of this methodology lie in its:
Breaking down complex bodies of work into manageable sections while preserving detailed relationships.
Maintaining logical consistency through proper handling of relationships.
Leveraging automated layout, strategic labeling, and meaningful color-coding.
Enabling cross-language analysis through context-aware translation.
By building Knowledge Graphs section by section, we can create navigable knowledge structures that capture local details and broader interconnections within a field of study. This approach supports knowledge organization, review, and communication across domains.