Data Import and Discretization
Open Data
As the first step, we start BayesiaLab’s Data Import Wizard by selecting Menu > Data > Open Data Source > Text File.
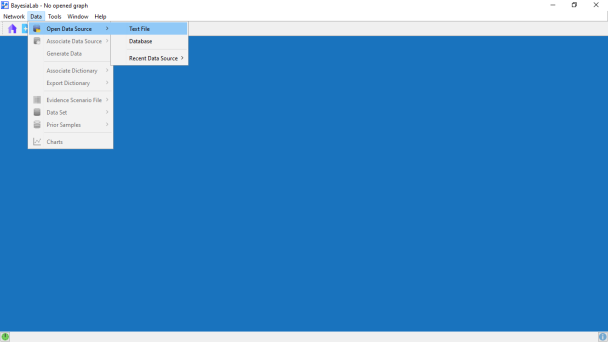
Then, we select the file AmesHousePriceData.csv, a comma-delimited, flat text file, which you can download here:


Data Import Wizard
This brings up the first screen of the Data Import Wizard, which previews the to-be-imported dataset. For this example, the coding options for Missing Values and Filtered Values are particularly important. By default, BayesiaLab lists commonly used codes that indicate an absence of data, e.g., #NUL! or NR (non-response). In the Ames dataset, a blank field (“ ”) indicates a Missing Value, and “FV” stands for Filtered Value. These are recognized automatically. If other codes were used, we could add them to the respective lists on this screen.

Clicking Next, we proceed to the screen that allows us to define variable types.
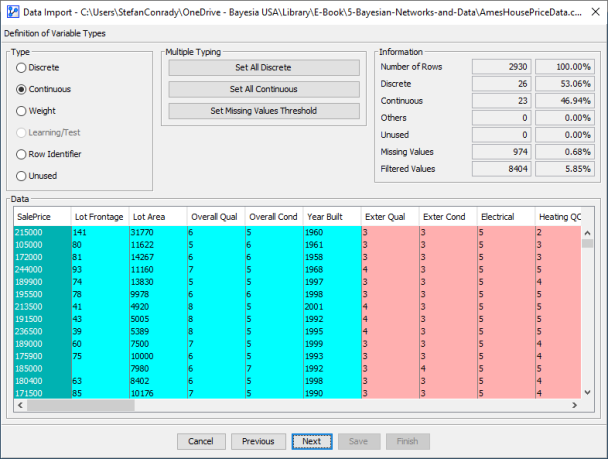
BayesiaLab scans all variables in the database and provides a best guess regarding the variable type. Variables identified as Continuous are shown in turquoise, and those identified as Discrete are highlighted in pastel red.
In BayesiaLab, a Continuous variable contains a wide range of numerical values (discrete or continuous), which need to be transformed into a more limited number of discrete states. Some other variables in the database only have very few distinct numerical values to begin with, e.g., [1,2,3,4,5], and BayesiaLab automatically recognizes such variables as Discrete. For them, the number of numerical states is small enough that creating bins of values is unnecessary. Also, variables containing text values are automatically considered Discrete.
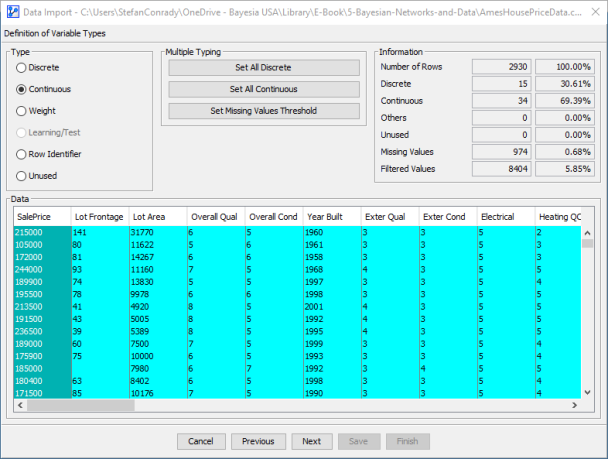
For this dataset, however, we need to make a number of adjustments to the suggested data types. For instance, we set all numerical variables to Continuous Nodes, including those highlighted in red that were originally identified as Discrete Nodes. As a result, all columns in the data preview of the Data Import Wizard are now shown in turquoise.
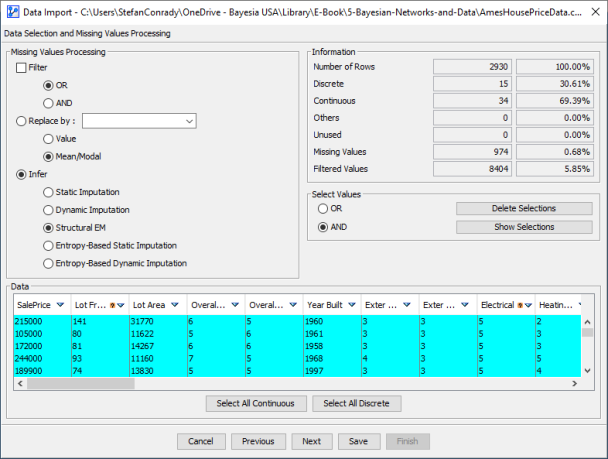
Given that our database contains some missing values, we need to select the type of Missing Values Processing in the next step. Instead of using ad hoc methods, such as pairwise or listwise deletion, BayesiaLab can leverage more sophisticated techniques and provide estimates (or temporary placeholders) for such missing values—without discarding any original data.
We will discuss Missing Values Processing in detail in Chapter 9. For this example, however, we leave the default setting of Structural EM.
Filtered Values
At this point, however, we must introduce a very special type of missing value for which we must not generate any estimates. We are referring to so-called Filtered Values. These are “impossible” values that do not or cannot exist—given a specific set of evidence, as opposed to values that do exist but are not observed. For example, for a home that does not have a garage, there cannot be any value for the variable , such as Attached to Home, Detached from Home, or Basement Garage. If there is no garage, there cannot be a garage type. As a result, it makes no sense to calculate an estimate of a Filtered Value. In a database, unfortunately, a Filtered Value typically looks identical to a “true” missing value that does exist but is not observed. The database typically contains the same code, such as a blank, NULL, N/A, etc., for both cases.
Therefore, instead of “normal” missing values, which can be left as-is in the database, we must mark Filtered Values with a specific code, e.g., “FV.” The Filtered Value declaration should be done during data preparation before importing any data into BayesiaLab. BayesiaLab will then add a Filtered State (marked with “*”) to the discrete states of the variables with Filtered Values and utilize a special approach for actively disregarding such Filtered States so that they are not taken into account during machine learning or for estimating effects.
Discretization
As the next step in the Data Import Wizard, all Continuous values must be discretized (or binned). We show a sequence of screenshots to highlight the necessary steps. The initial view of the Discretization and Aggregation step appears.
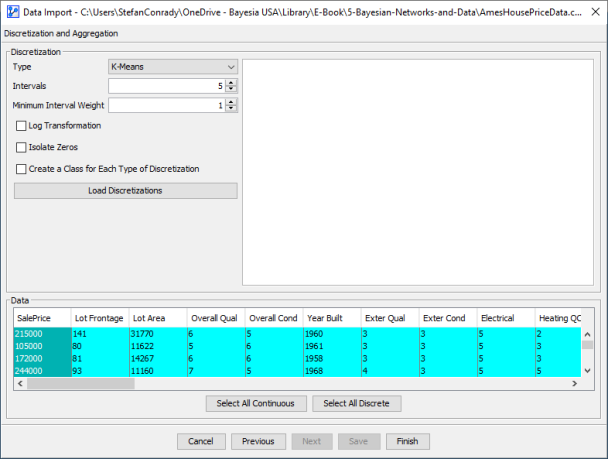
By default, the first column is highlighted, which happens to be , the variable of principal interest in this example. Instead of selecting any available automatic discretization algorithms, we pick Manual from the Type drop-down menu, which brings up the Cumulative Distribution Function (CDF) of the variable.

By clicking Density Function, we can bring up the Probability Density Function (PDF) of .
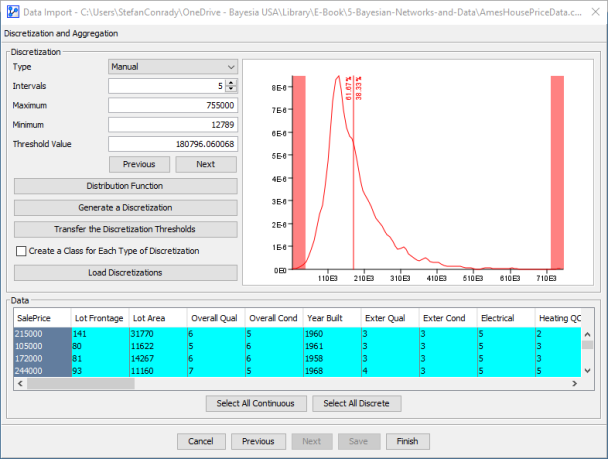
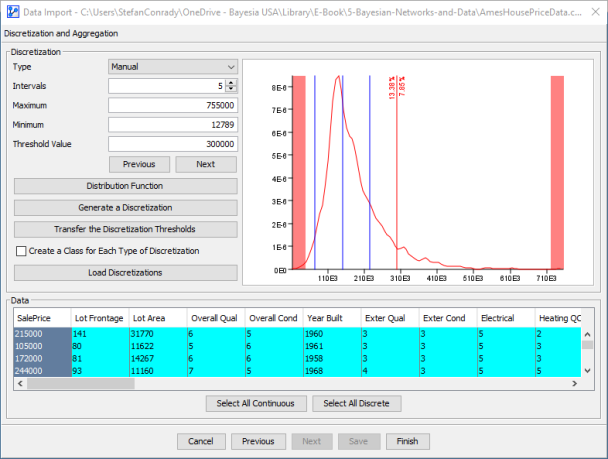
Either view allows us to examine the distribution and identify any salient points. We stay on the current screen to set the thresholds for each discretization bin. In many instances, we would use an algorithm to define bins automatically unless the variable will serve as the target variable. In that case, we usually rely on available expert knowledge to define the binning. In this example, we wish to have evenly-spaced, round numbers for the interval boundaries. We add boundaries by right-clicking on the plot (right-clicking on an existing boundary removes it again). Furthermore, we can fine-tune a threshold’s position by entering a precise value in the Threshold Value field. We use {75000, 150000, 225000, 300000} as the interval boundaries.
Tree Discretization
Now that we have manually discretized the target variable (column highlighted), we still need to discretize the remaining continuous variables. However, we will take advantage of an automatic discretization algorithm for those variables.
We click Select All Continuous. BayesiaLab automatically excludes from this selection because we have already discretized it.
Numerous automatic discretization algorithms are available, but for the purpose of this example, we only consider the bivariate Tree discretization algorithm.
Please see the main entry for Discretization in this library for a detailed description of all available algorithms.
As its name suggests, the Tree discretization algorithm machine-learns a decision tree that uses the to-be-discretized variable for representing the conditional probability distributions of the target variable given the to-be-discretized variable. Once the Tree is learned, it is analyzed to extract the most useful thresholds. This is the method of choice in the context of Supervised Learning, i.e., when planning to machine-learn a model to predict the target variable.
At the same time, we do not recommend using Tree in the context of Unsupervised Learning. The Tree algorithm creates bins that are biased toward the designated target variable. Naturally, emphasizing one particular variable would run counter to the intent of Unsupervised Learning.
Note that if the to-be-discretized variable is independent of the target variable, it will be impossible to build a tree, and BayesiaLab will prompt the selection of a univariate discretization algorithm.
In this example, we focus our analysis on , which can be considered a type of Supervised Learning. Therefore, we discretize all continuous variables with the Tree algorithm, using as the Target variable. Note the Target must either be a Discrete variable or a Continuous variable that has already been manually discretized, which is the case for .
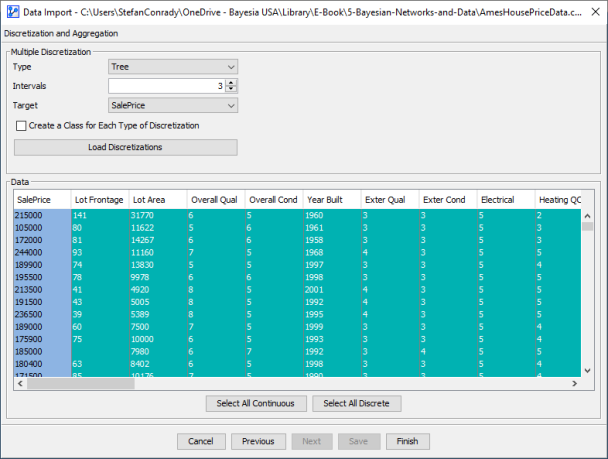
Clicking Finish completes the import process.
The import process concludes with a pop-up window that offers to display the Import Report.

Clicking Yes brings up the Import Report, which can be saved in HTML format. It lists the discretization intervals of the Continuous variables, the States of the Discrete variables, and the discretization method used for each variable.

Graph Panel
Once we close out this report, we can see the result of the import process. All the imported variables are now represented as nodes on the Graph Panel. The dashed borders of some nodes indicate that the corresponding variables were discretized during data import.
Furthermore, we can see icons that indicate the presence of Missing Values and Filtered Values in the respective nodes.
The lack of warning icons on any nodes indicates that all their parameters, i.e., their marginal probability distributions, were automatically estimated upon data import.
To verify, we open the Node Editor of (Node Context Menu > Edit > Probability Distribution > Probabilistic) and check the node’s marginal distribution.
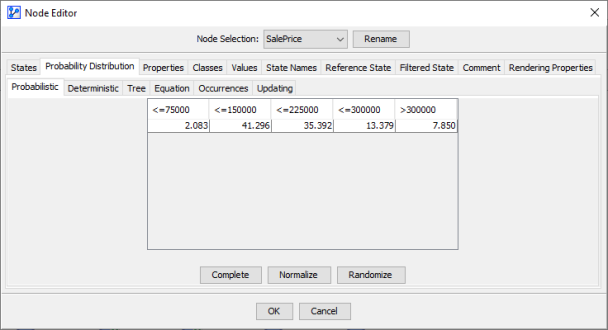
Clicking on the Occurrences tab shows the observations per cell, which were used for the Maximum Likelihood Estimation of the marginal distribution.

Workflow Animation
The following animation shows all the above steps in a continuous workflow.