Resampling (9.0)
Context
Tools | Resampling
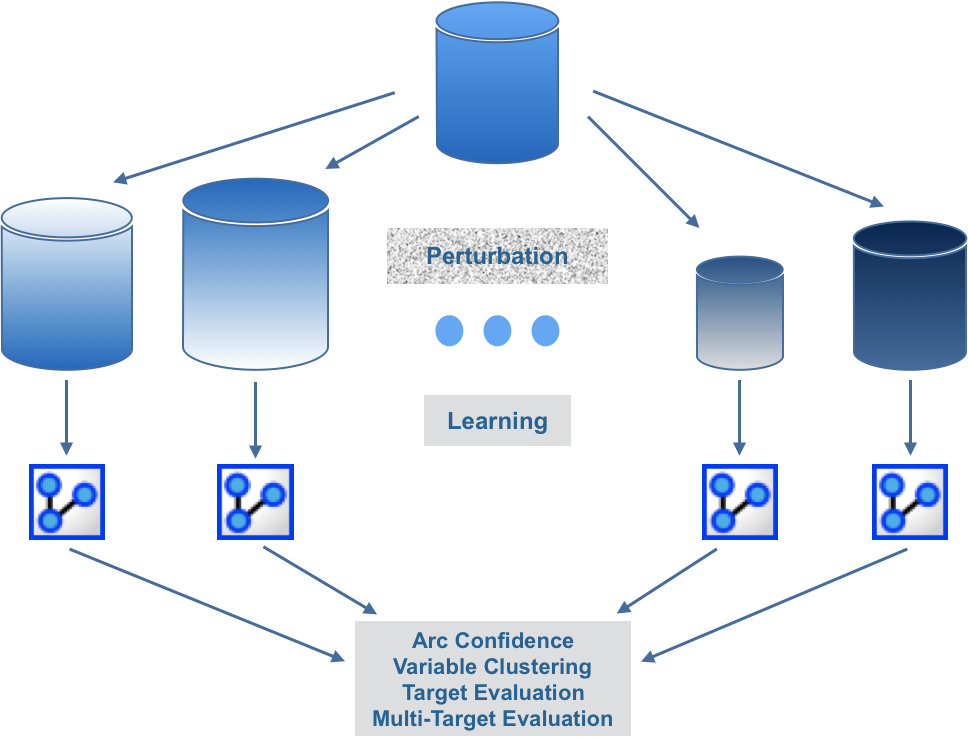
Resampling is used to measure the stability of the machine-learned results:
- Various data sets are generated from the original data set with one of our resampling methods,
- Machine learning is iteratively applied on each data set,
- The results are analyzed and compared with the current network.
History
- *Resampling,** formerly called Cross-Validation, has been updated in versions 5.0.2, 5.0.4, 5.1, 5.3, 5.4, 6.0, and 7.0.
Updated Feature: Data Perturbation
As of version 9.0, Data Perturbation can be done locally at the particle level, but also globally, at the data set level, with the possibility to generate a random Structural Coefficient.
Furthermore, the perturbation at the particle level is now drawn uniformly between 0 and 2, without any decay factor, which allows us to get the exact same level of perturbation in all generated data sets.
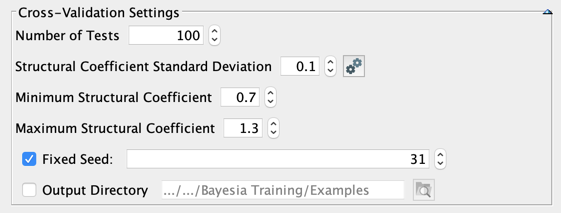
When the Structural Coefficient Standard Deviation is set to a value greater than 0, a random coefficient is drawn, for each perturbed data set, from a Normal distribution with a mean equal to the Default Structural Coefficient (the one associated with the current Bayesian network), and the specified standard deviation.
Clicking  allows getting the range of coefficients that can be drawn with the Default Structural Coefficient and Structural Coefficient Standard Deviation. It is then possible to edit the Minimum and Maximum Structural Coefficients.
allows getting the range of coefficients that can be drawn with the Default Structural Coefficient and Structural Coefficient Standard Deviation. It is then possible to edit the Minimum and Maximum Structural Coefficients.