Generating the Test Dataset
To begin this exercise, we use BayesiaLab to produce the test data that we will later use for evaluating the Missing Values Processing methods.
We can directly generate data according to the joint probability distribution encoded by the Reference Network: Menus > Data > Generate Data.
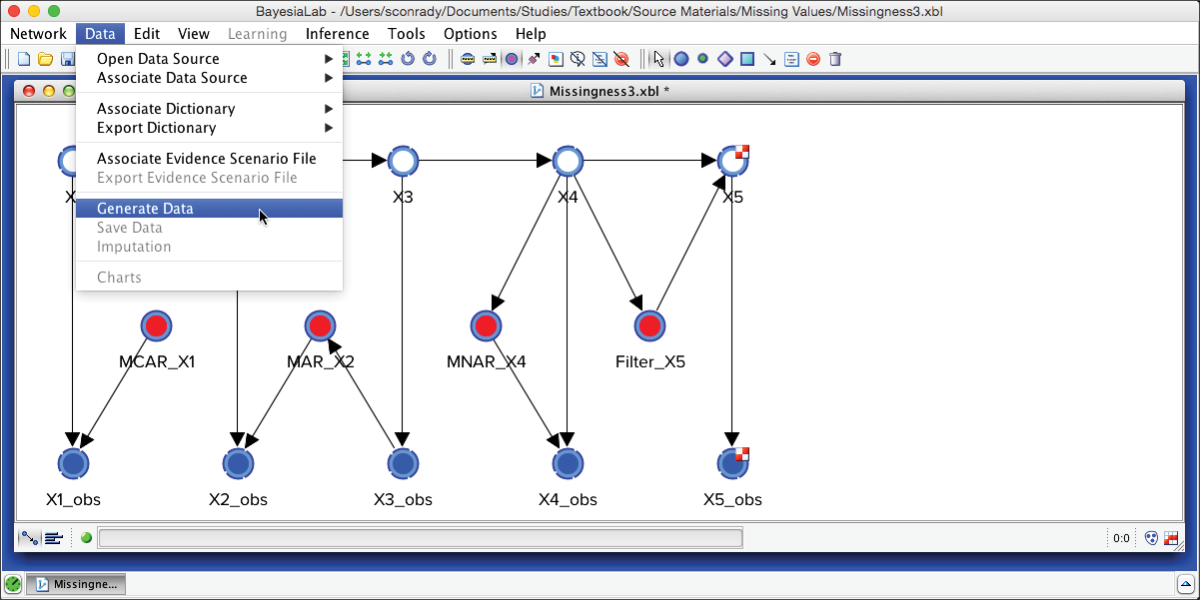
Next, we must specify whether to generate this data internally or externally. For now, we generate the data internally, which means that we associate data points with all nodes. This includes missing values and Filtered Values according to the reference network.
For the Number of Examples (i.e., cases or records), we set 10,000.
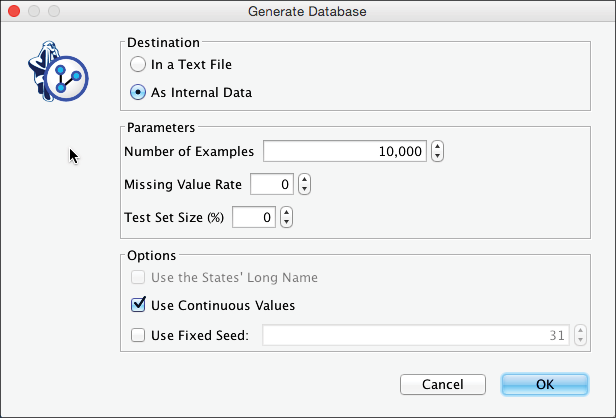
The Database icon signals that a dataset is now associated with the network. Additionally, we can see the number of cases in the database at the top of the Monitor Panel.
Now that this data exists inside BayesiaLab, we need to export it, so we can truly start “from scratch” with the test dataset. Also, regarding realism, we only want to make the observable variables available rather than all variables. We first select the nodes through and then select Menus > Data > Data Set > Save from the main menu.
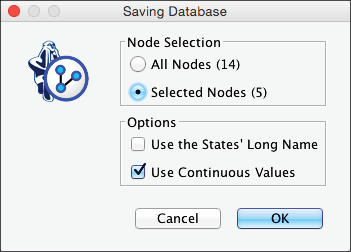
Next, we confirm that we only want to save the Selected Nodes, i.e., the observable variables.
Upon specifying a file name and saving the file, the export task is complete.
A quick look at the CSV file confirms that the newly generated data contain missing and Filtered Values, as indicated with question marks (?) and asterisks (*), respectively.
Now that we have produced a test dataset with all types of missingness, we forget our reference model to start “from scratch.” We approach this dataset as if this were the first time we see it, without any assumptions and without any background knowledge. This provides us with a suitable test case for BayesiaLab’s range of missing values processing methods.