Data Import
Data Import
We use BayesiaLab’s Data Import Wizard to load all 459 time series into memory from the data file:

BayesiaLab automatically detects the column headers, which contain the ticker symbols that we will use as variable names (a ticker symbol is an abbreviation used to uniquely identify publicly traded stocks).
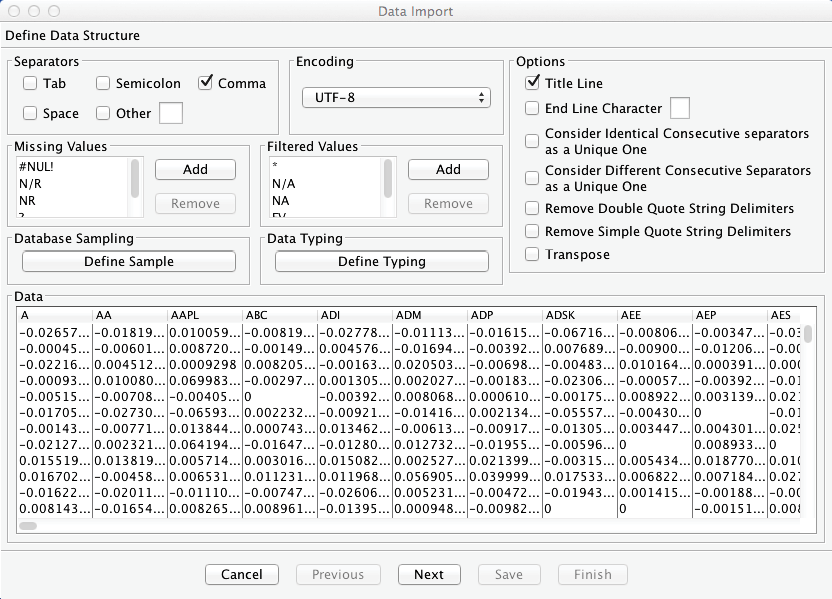
The next step identifies the variable types contained in the dataset and, as expected, BayesiaLab finds 459 Continuous variables.
There are no missing values in this database, so the next step of the Data Import Wizard can be skipped entirely. We still show this step below for reference, although all options are grayed out.
Data Discretization
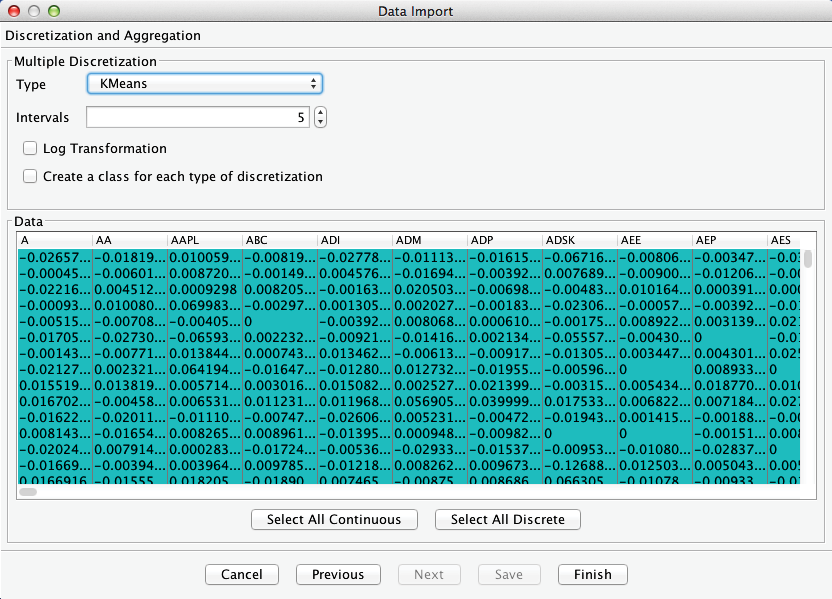
While we can defer a discussion of Missing Values Processing, for now, we must carefully consider our options in the next step of the Data Import Wizard. Here, we need to discretize all Continuous variables, which means all 459 variables in our case. In the context of Unsupervised Learning, we do not have a specific target variable. Hence, we have to choose one of the univariate discretization algorithms. Following the recommendations presented in Chapter 6, we choose K-Means. Furthermore, given the number of available observations, we aim for a discretization with 5 bins, as per the heuristic discussed in Chapter 6 under Discretization Intervals.
While helpful, any such heuristics should not be considered conclusive. Only once a model is learned can we properly evaluate the adequacy of the selected discretization. In BayesiaLab, we also have access to the Discretization function again anytime after completing the Data Import Wizard, which makes experimentation with different discretization methods and intervals very easy. In the Modeling Mode F4, we can start a new discretization with Menu > Learning > Discretization.
Before proceeding with the automatic discretization of all variables, we examine the type of density functions that we can find in this dataset. We use the built-in plotting function for this purpose, which is available in the next step of the Data Import Wizard.

After selecting Manual from the Discretization drop-down menu and then clicking Switch View, we obtain the probability density function of the first variable A.

Without formally testing it for normality, we judge that the distribution of A (Agilent Technologies Inc.) does resemble the shape of a Normal distribution. In fact, the distributions of all variables in this dataset appear fairly similar, which further supports our selection of the K-Means algorithm. We click Finish to perform the discretization. A progress bar is shown to report the progress.
Modeling Mode
After completing the Data Import Wizard, the variables are presented in the Graph Panel. The original variable names, which were stored in the first row of the dataset, become our Node Names.

At this point, it is practical to add Node Comments to associate full company names with the short ticker symbols. We use a Dictionary file for that purpose:


This file can be loaded into BayesiaLab via Menu > Data > Associate Dictionary > Node > Comments.

Once the Node Comments are loaded, a small call-out symbol () appears next to each Node Name, confirming that associating the Dictionary completed successfully.

As the name implies, selecting Menu > View > Display Node Comments reveals the full company names.

Node Comments can be displayed for either all nodes or only for selected ones.

Data Import Review
Before proceeding with the first learning step, we recommend switching to the Validation Mode F5 to verify the results of the import and discretization.

This gives us an opportunity to compare the variables’ statistics with our understanding of the domain. At first glance, mean values of near-zero for all distributions might suggest that stock prices remained “flat” throughout the observation period. For the S&P 500 index, this was actually true. However, it could not be true for all individual stocks, given that the Apple stock, for instance, increased ten-fold in value between 2005 and 2010. The seemingly low returns are due to the fact that we are studying daily returns rather than annual returns. On that basis, even the rapid appreciation of the Apple stock translates into an average daily return of “only” 0.2%. A “sanity check” of this kind is the prudent thing to do before proceeding to machine learning.