Multiple Clustering (9.0)
Context
Learning | Clustering | Multiple Clustering
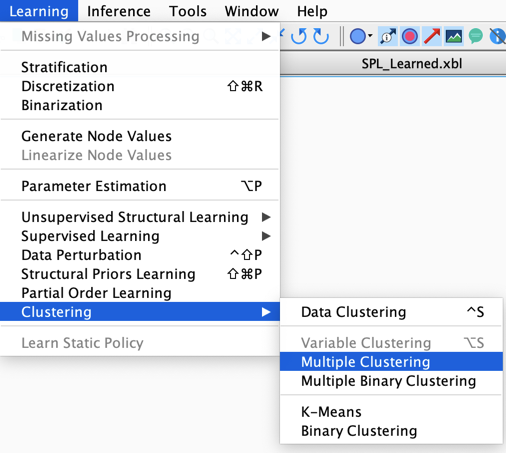
Multiple Clustering is one of the steps of our Probabilistic Structural Equation Model (PSEM) (opens in a new tab) workflow. It consists of iteratively using Data Clustering on subsets of data defined by the Classes [Factor_i] to create Latent/Factor variables that represent the hidden causes that have been sensed by Manifest variables.
History
Multiple Clustering (opens in a new tab) has been updated in version 5.0.2 (opens in a new tab), 5.0.4 (opens in a new tab), and 5.0.7 (opens in a new tab).
New Feature: Arc Dictionary
When the option Connect Factors to their Manifest Variables is checked, the final network comes with a set of naïve networks.
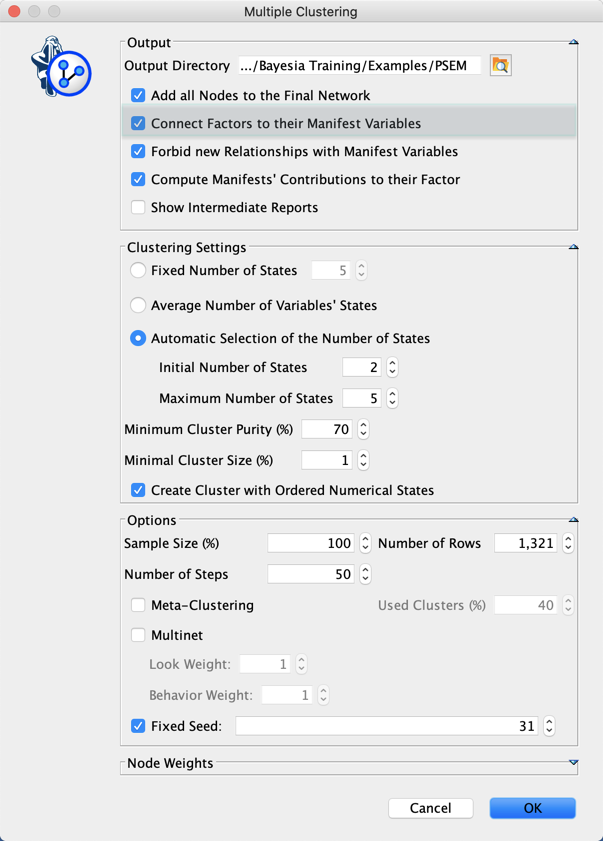
A dictionary of arcs is now automatically created when this option is checked. This allows you to use any structural learning algorithm to learn the relationships between the Factors (i.e. not only Taboo, EQ, and TabooEQ), even an algorithm that first Delete All Arcs. All you have to do is use Data | Associate Dictionary | Arc | Arcs with the created dictionary to bring back the deleted arcs between the Factors and their Manifest variables. The dictionary is saved in the specified Output Directory under the name of the original network suffixed with "_Final_arcs.txt".
Example
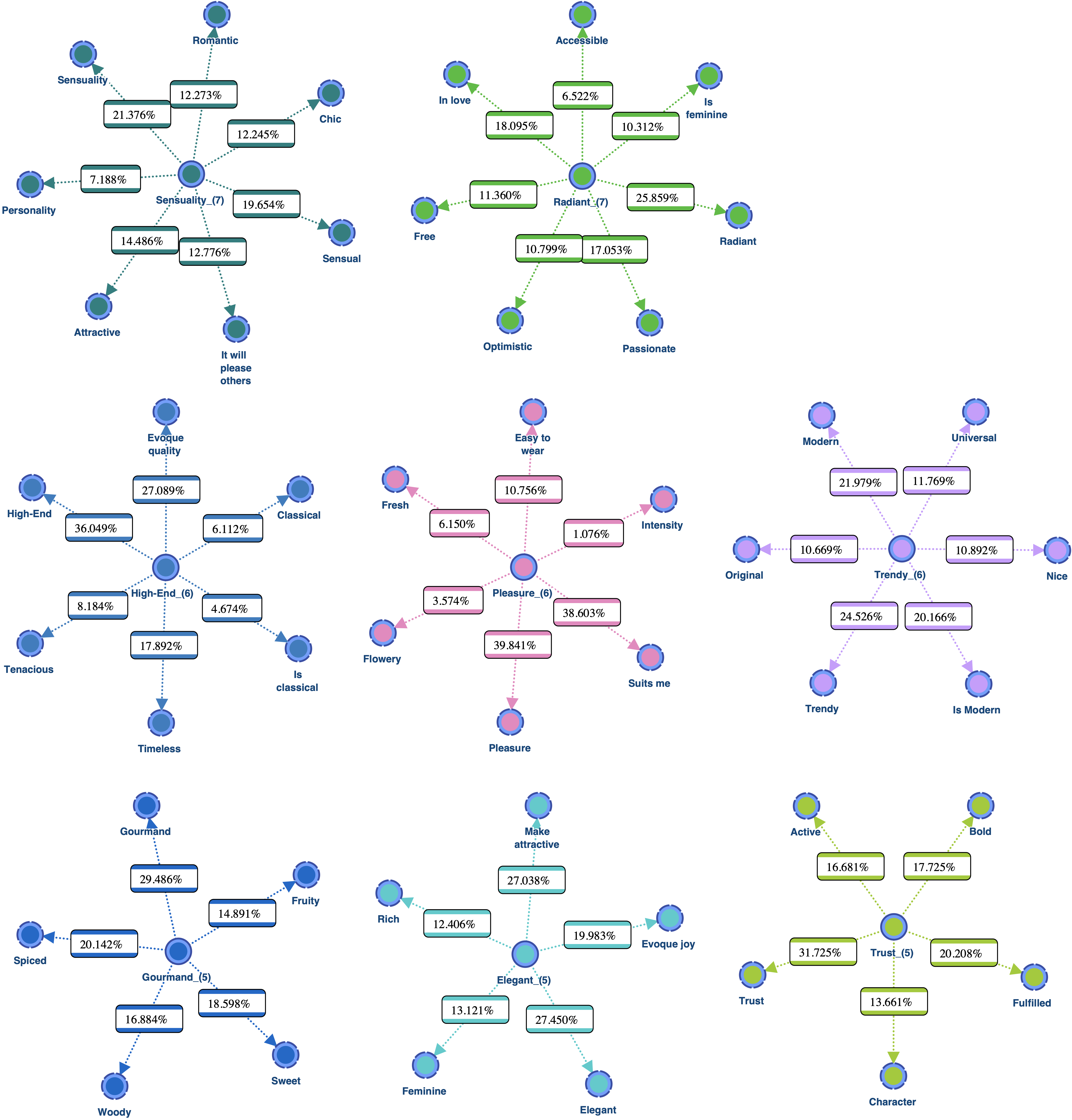
The network below is the final network generated by Multiple Clustering. It contains the Factors that represent the hidden causes of the 8 classes of variables identified with Variable Clustering (opens in a new tab).
Below is an excerpt from the dictionary: