Data Import and Discretization
Our modeling process begins with importing the dataset. You can download this dataset in CSV format via the link below or from data.world .

Note that this dataset from the Wisconsin Breast Cancer Database differs from the one we used in the original, printed edition of this book.
Data Import Wizard
We start the Data Import Wizard with Menu > Data > Open Data Source > Text File.
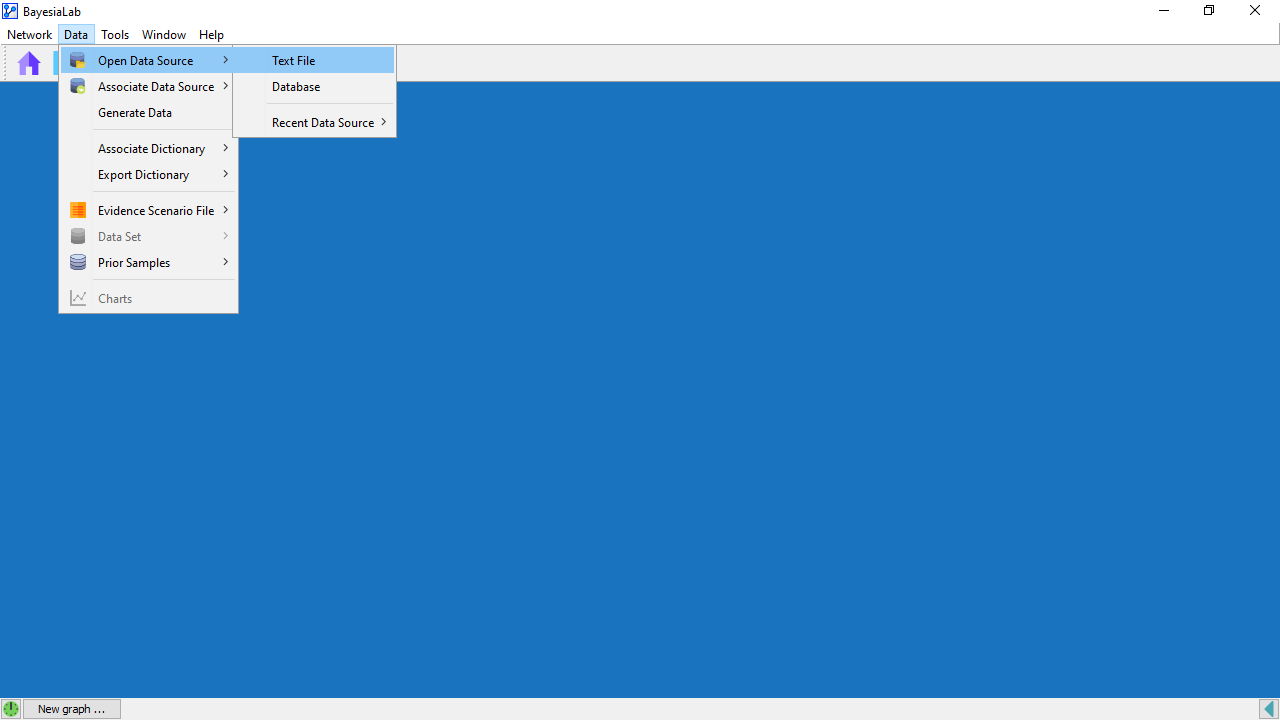
Next, we select the file WBCD2.CSV. Then, the Data Import Wizard guides us through the required steps.
In Step 1 of the Data Import Wizard, we click on Define Learning/Test Sets and specify to set aside a Test Set from the to-be-imported dataset.
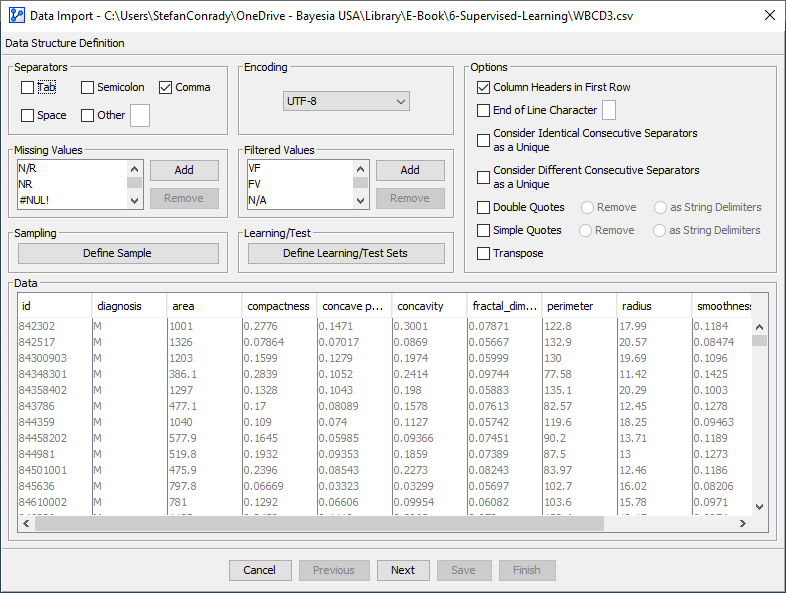
We specify a random sample of 20% of the entire dataset to serve as a Test Set. The remaining 80% will serve as the Learning Set.
If you follow this tutorial and want to replicate the exact numerical values we present here, please check Fixed Seed under Options and set its value to 31. This ensures that the random number generator produces the same Learning Set and Test Set split that we use here.
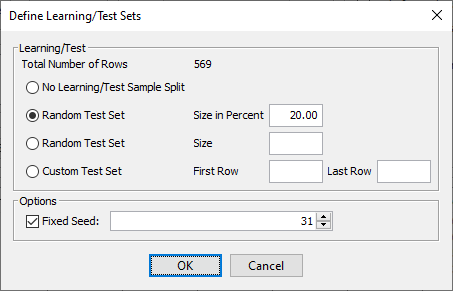
In Step 2 of the Data Import Wizard BayesiaLab suggests a data type for each variable.
It identifies the diagnosis variable as Discrete, and all the feature variables are interpreted as Continuous. These default assignments are all correct.
We only need to correct the variable id, which BayesiaLab initially considers Continuous. However, id is a code to identify each patient, so we must specify it as a Row Identifier.
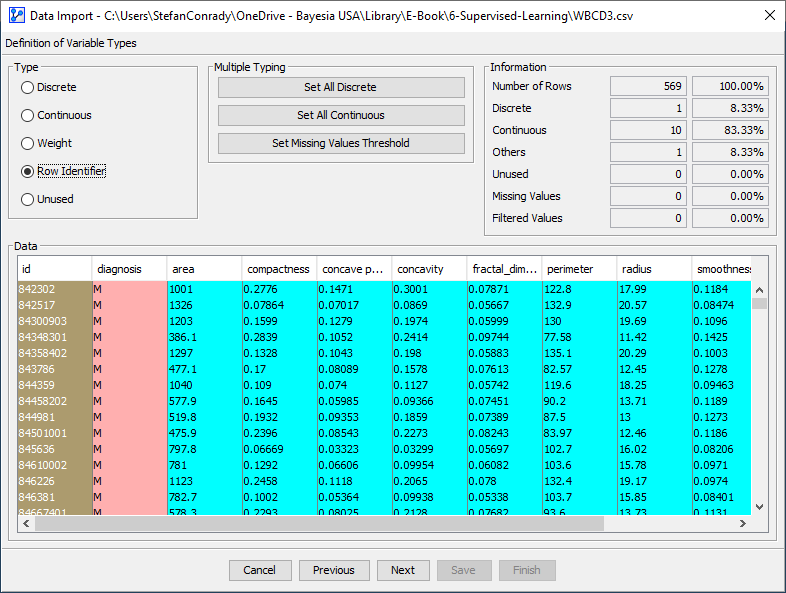
In Step 3 of the Data Import Wizard, no action is required. Our dataset has no missing values, so applying any Missing Values Processing is unnecessary.
However, given that many datasets do contain missing values, we devoted an entire chapter to dealing with that problem. Please see Chapter 9: Missing Values Processing.
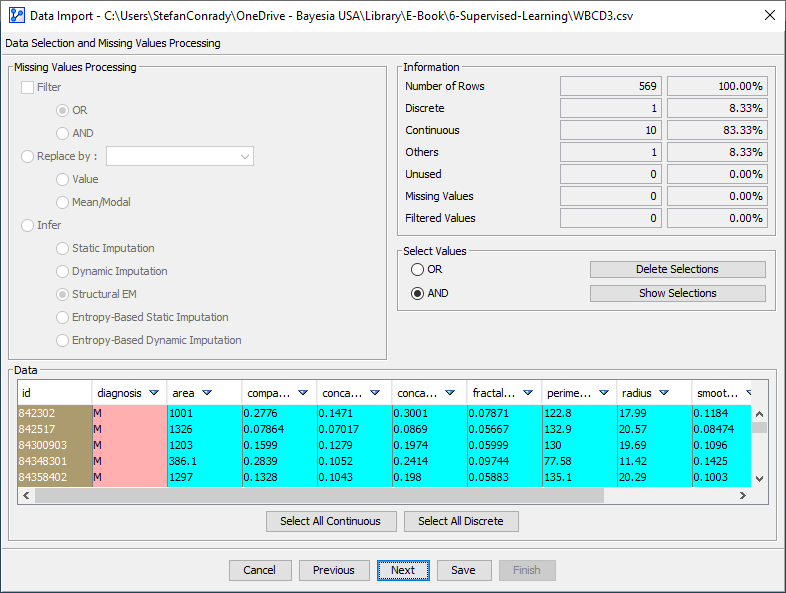
In Step 4 of the Data Import Wizard, we need to discretize the Continuous variables in the dataset. Even though we could specify a discretization method for each Continuous variable separately, we want to apply the same algorithm to all.
So, we click Select All Continuous, and all Continuous variables are highlighted in the data table. The Discretization Type and all related options will now apply to all the selected nodes.
Given that we are building a model to predict the target variable diagnosis, it makes perfect sense to discretize all the continuous feature variables with that objective in mind.
Thus, we choose the Tree algorithm from the drop-down menu in the Multiple Discretization panel. The Tree algorithm attempts to find discretization thresholds so that each feature variable’s information gain with regard to the target variable is maximized.
Note that the Tree algorithm requires a Target, which has to be a Discrete variable or a Continuous variable that has already been discretized. In our context, diagnosis is Discrete and, therefore, available from the Target dropdown menu.
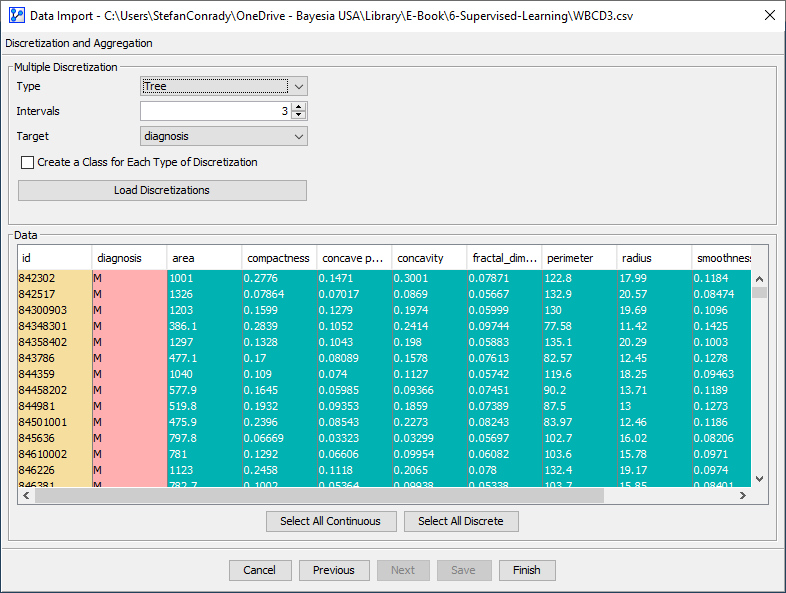
Note that the discretization algorithm only uses the records from the Learning Set for creating the discretization threshold. If a Learning/Test Set split is specified in Step 1 of the Data Import Wizard, BayesiaLab automatically restricts the discretization algorithms to the Learning Set.
While you can also create a Learning/Test Set split after completing the Data Import Wizard, it would compromise the Test Set. Such a Test Set would no longer be properly out-of-sample as it would have contributed to the discretization.
Discretization Intervals
Bayesian networks are non-parametric probabilistic models. Therefore, there is no hypothesis with regard to the form of the relationships between variables (e.g., linear, quadratic, exponential, etc.). However, this flexibility has a cost. The number of observations necessary to quantify probabilistic relationships is higher than those required in parametric models. We use the heuristic of five observations per probability cell, which implies that the bigger the size of the probability tables, the larger must be the number of observations.
Two parameters affect the size of a probability table: the number of parents and the number of states of the parent and child nodes. A machine-learning algorithm usually determines the number of parents based on the strength of the relationships and the number of available observations. The number of states, however, is our choice, which we can set by means of Discretization (for Continuous variables) and Aggregation (for Discrete variables).
We can use our heuristic of five observations per probability cell to help us with the selection of the number of discretization Intervals:
We usually look for an odd number of states to be able to capture non-linear relationships. Given that we have a relatively small learning set of only 456 observations, we should estimate how many parents would be allowed based on this heuristic and a discretization with 3 states:
- No parent: 3×5=15
- One parent: 3×3×5=45
- Two parents: 3×3×3×5=135
- Three parents: 3×3×3×3×5=405
- Four parents: 3×3×3×3×3×5=1,215
Considering a discretization with 5 states, we would obtain the following:
- No parent: 5×5=25
- One parent: 5×5×5=125
- Two parents: 5×5×5×5=625
By using this heuristic, we hypothesize about the size of the biggest CPT of the to-be-learned Bayesian network and multiply this value by 5. Experience tells us that this is a rather practical heuristic, which typically helps us find a structure. However, this is by no means a guarantee that we will find a precise quantification of the probabilistic relationships.
Indeed, our heuristic is based on the hypothesis that all the cells of the CPT are equally likely to be sampled. Of course, such an assumption cannot hold as the sampling probability of a cell depends on its probability, i.e., either a marginal probability if the node does not have parents, or if it does have parents, a joint probability defined by the parent states and the child state.
Given our 456 observations and the scenarios listed above, we select a discretization scheme with a maximum of 3 states. This is a maximum in the sense that the Tree discretization algorithm could return 2 states if 3 were not needed. This happens to be the case for and .
Import Report
Upon clicking Finish, BayesiaLab imports and discretizes the entire dataset and concludes with Step 5 of the Data Import Wizard by offering an Import Report.
Clicking Yes brings up the Import Report.
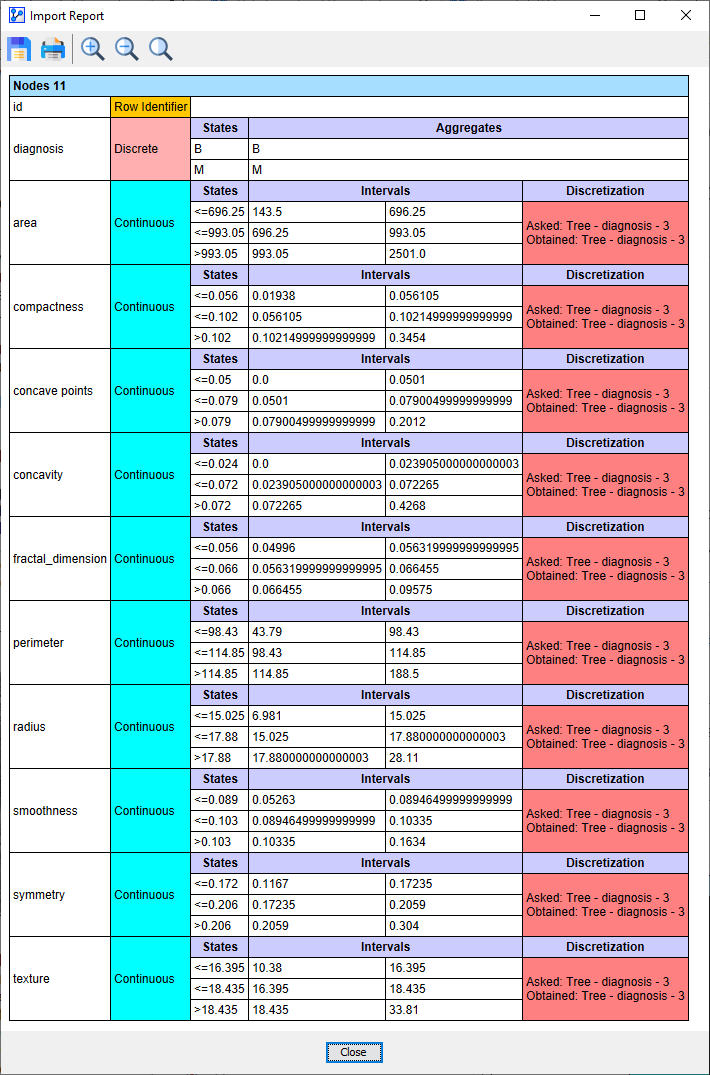
It is interesting to see that all the variables have indeed been discretized with the Tree algorithm and that all Discretization Intervals are variable-specific.
This means that all the variables are marginally dependent on the Target Node (and vice versa). This is promising: the more dependent variables we have, the easier it should be to learn a good model for predicting the Target Node.
Graph Window
Upon closing the Import Report, we see a representation of the newly imported database as a fully unconnected Bayesian network in the Graph Window.
Additionally, there is a tag on the database icon in the lower right corner of the Graph Window: The icon confirms that we have a Learning/Test Set split in place.
State Names
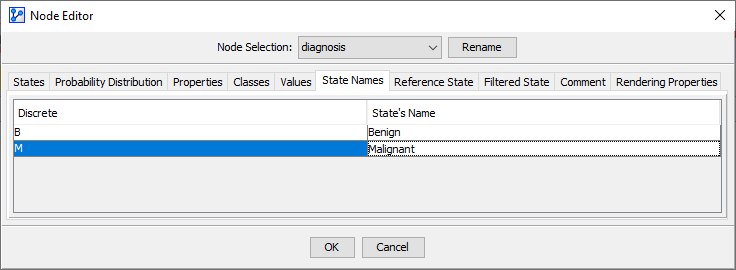
In the dataset, the variable contained the codes B and M, representing Benign and Malignant, respectively. For reading the analysis reports, however, it will be easier to work with a proper State Name instead of an abbreviation.
By double-clicking the node , we open the Node Editor and then go to the State Names tab. There, we associate States B and M with new State Names:
- B → Benign
- M → Malignant
With all variables represented as nodes in the Graph Window, we are ready to proceed to Supervised Learning in this tutorial.