Batch Joint Probability
For each record of the database or each evidence set of the associated Evidence Scenario File, nodes are observed using the record values (except for nodes declared as Not Observable and those with missing values). The joint probability of this evidence is computed with the Bayesian network.
The results are stored in an exploitation file that takes the selected fields of the input file and associates, for each case, the computed joint probability of the evidence.
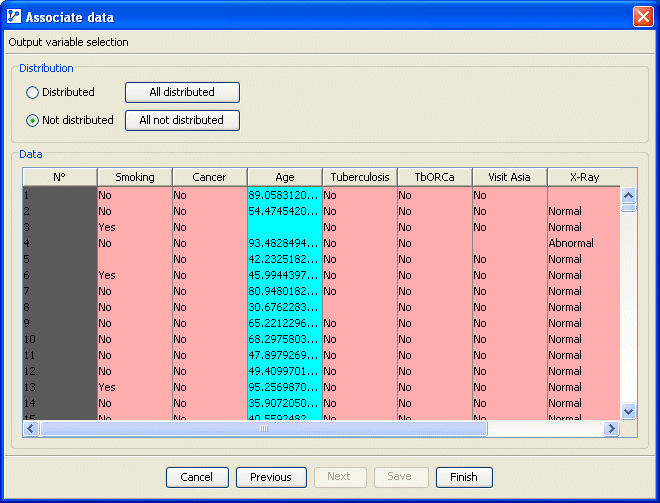
If the data source is an external database, the fields of the input file that are included in the exploitation file are selected via the wizard illustrated below:
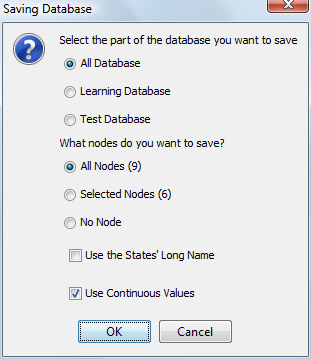
If the data source is the associated database, a dialog allows the user to choose which part of the database (all, learning, or test) the operation is performed on and which nodes will be saved in the destination file. It is also possible to choose whether the states’ long names are used and whether the continuous values are saved:
Sorting the resulting file with respect to this joint probability can help detect atypical records, i.e., outliers (cases with a very low joint probability), by taking into account all the variables.