Network Performance Analysis Overall — Learning Set
Context
- This Overall Performance Report evaluates a network with regard to a dataset that does not have a Learning/Test Set split.
- If your dataset does have a Learning/Test Set split, please see Report for Learning and Test Set.
Notation
- denotes the Bayesian network to be evaluated.
- represents the Dataset from which network was learned.
- represents evidence . Evidence refers to an n-dimensional observation, i.e., one row or record in the dataset , from which the Bayesian network was learned.
- refers to the number of observations in the dataset .
- refers to a Complete or fully connected network, in which all nodes have a direct link to all other nodes. Therefore, the complete network is an exact representation of the chain rule. As such, it does not utilize any conditional independence assumptions for representing the Joint Probability Distribution.
- represents a Unconnected network, in which there are no connections between nodes, which means that all nodes are marginally independent.
Example
To explain and illustrate the Overall Performance Report, we use a Bayesian network model that was generated with one of BayesiaLab’s Unsupervised Learning algorithms. This network is available for download here:
Overall Performance Report
Density & Distribution Function
The top part of the Report features a plot area, which offers two views:
-
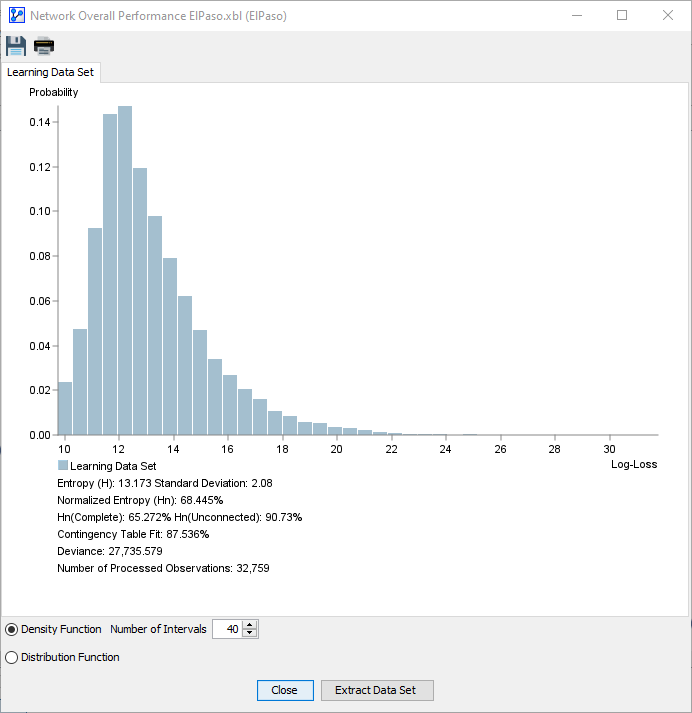
Density Function
- The x-axis represents the Log-Loss values in increasing order.
- The y-axis shows the probability density for each Log-Loss value on the x-axis.
-
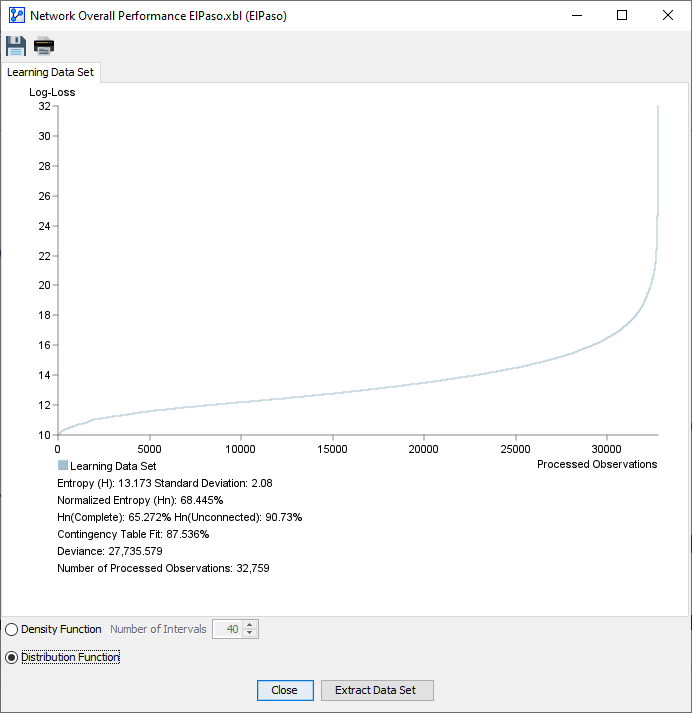
Distribution Function
- The observations in the dataset are sorted in ascending order according to their Log-Loss values:
- The x-axis shows the observation number.
- The y-axis shows the Log-Loss value corresponding to each observation.
- The observations in the dataset are sorted in ascending order according to their Log-Loss values:
Click on the thumbnail images to enlarge the screenshots of each view:
| Density Function (Histogram) | Distribution Function |
|---|---|
 |  |
The radio buttons on the bottom-left of the window allow you to switch the view between the Density function (Histogram) and the Distribution function.
Either view provides a visualization of the Log-Loss values for all observations in the dataset given the to-be-evaluated Bayesian network . Thus, the plots provide you with a visual representation of how well the network fits the dataset .
The Density view, in particular, allows you to judge the fit of the network by looking at the shape of the Log-Loss histogram.
The bars at the low end of the x-axis represent well-fitting observations. Conversely, the bars that are part of the long tail on the right represent poorly fitting observations.
While in the Density view, you can adjust the Number of Intervals used for the histogram within a range from 1 to 100, as illustrated in the following animation:
Log-Loss
The computation of Log-Loss values is at the very core of this Overall Performance Report.
The Log-Loss value reflects the number of bits required to encode the n-dimensional evidence , i.e., an observation, row, or record in the dataset given the to-be-evaluated Bayesian network :
where is the joint probability of evidence computed by the Bayesian network :
In other words, the lower the probability of evidence given the Bayesian network , the higher is the Log-Loss . As such, the Log-Loss value of an observation represents its fit to network B.
So, to produce the plots and all related metrics, BayesiaLab has to perform the following computations:
- , the Log-Loss value for each observation/evidence in the Learning Set based on the learned and to be-evaluated Bayesian network B.
- , the Log-Loss value for each observation/evidence in the Learning Set based on the complete network C.
- , the Log-Loss value for each observation/evidence in the Learning Set based on the unconnected network .
The following Log-Loss Table is an extract of the first ten rows each from the Learning Set D_L with the computed Log-Loss values for each record:
Log-Loss Table
| Evidence E from the Dataset D | Computed Values | |||||||
|---|---|---|---|---|---|---|---|---|
| Month | Hour | Temperature | Shortwave Radiation (W/m2) | Wind Speed (m/s) | Energy Demand (MWh) | Log-Loss (Bayesian Network) | Log-Loss (Complete Network) | Log-Loss (Unconnected Network) |
| 8 | 18 | 36.57 | 213.6 | 2 | 1574 | 13.42 | 15.00 | 22.06 |
| 8 | 19 | 36.04 | 105.91 | 1.9 | 1574 | 13.55 | 15.00 | 21.68 |
| 8 | 20 | 34.71 | 42.72 | 2.14 | 1485 | 11.93 | 11.68 | 19.4 |
| 8 | 21 | 33.94 | 0 | 2.75 | 1470 | 11.92 | 12.00 | 17.73 |
| 8 | 22 | 33.19 | 0 | 3.55 | 1378 | 11.81 | 11.09 | 17.73 |
| 8 | 23 | 32.38 | 0 | 4.21 | 1249 | 13.69 | 12.41 | 16.93 |
| 8 | 0 | 31.56 | 0 | 4.5 | 1110 | 12.91 | 12.19 | 16.93 |
| 8 | 1 | 30.6 | 0 | 4.8 | 1031 | 13.21 | 13.41 | 16.93 |
| 8 | 2 | 29.66 | 0 | 4.9 | 975 | 11.16 | 11.68 | 14.7 |
| 8 | 3 | 29.02 | 0 | 4.6 | 944 | 10.85 | 11.19 | 14.7 |
| ⁞ | ⁞ | ⁞ | ⁞ | ⁞ | ⁞ | ⁞ | ⁞ | ⁞ |
| Mean | 13.17 | 12.56 | 17.46 | |||||
| Std. Dev. | 2.08 | 1.40 | 2.17 | |||||
| Minimum | 9.75 | 9.48 | 14.37 | |||||
| Maximum | 31.78 | 15.00 | 31.06 | |||||
| Normalized | 68.44% | 65.27% | 90.73% |
Performance Measures
Below the plot area of the window, the Overall Performance Report shows a range of quality measures. 
For clarity, we match up the report’s labels to the notation introduced at the beginning of this topic.
| Label in Report | Notation in this Topic | Explanation |
|---|---|---|
| Entropy (H) | Mean of Log-Loss Values of all observations in the dataset | |
| Normalized Entropy (Hn) | ||
| Hn(Complete) | ||
| Hn(Unconnected) | ||
| Contingency Table Fit | see Normalized Entropies | |
| Deviance | ||
| Number of Processed Observations |
Entropy
The first item, Entropy , refers to the evaluated network . Hence, it is also denoted Entropy elsewhere in this topic for clarity.
More specifically, Entropy is the arithmetic mean of all Log-Loss values of each observation in the dataset given network . In the Data Table above, Entropy is highlighted.
Normalized Entropies
With Entropy not being directly interpretable as a standalone value, the report includes the Normalized Entropy . Here, Normalized Entropy also refers to the evaluated network .
Note that in the standalone topic on Entropy, we defined Normalized Entropy on the basis of a single variable with one set of states.
Here, however, we need to consider that we have several variables with differing numbers of states. So, we require a more general definition of Normalized Entropy:
where
- is the set of variables in network .
- is the size of the Joint Probability Distribution, i.e., the number of state combinations defined by all variables in .
With that, we can calculate the value:
Furthermore, the report provides the Normalized Entropies for a complete (fully-connected) network and the unconnected network .
Complete (Fully-Connected) Network
refers to the Normalized Entropy computed from all observations with a complete network (depicted below), which is the best-fitting representation of the observations.
Unconnected Network
is the Normalized Entropy obtained with an unconnected network , which is the worst-fitting representation of the observations.
Contingency Table Fit (CTF)
Contingency Table Fit (CTF) measures the quality of the representation of the Joint Probability Distribution by a Bayesian network in comparison to a complete network .
BayesiaLab’s CTF is defined as:
where
- is the entropy of the dataset with the unconnected network .
- is the entropy of the dataset with the network .
- is the entropy of the dataset with the complete network .
Interpretation
- is equal to 100 if the Joint Probability Distribution is represented without any approximation, i.e., the entropy of the evaluated network is the same as the one obtained with the complete network .
- is equal to 0 if the Joint Probability Distribution is represented by considering that all the variables are independent, i.e., the entropy of the evaluated network is the same as the one obtained with the unconnected network .
- can also be negative if the parameters of network do not correspond to the dataset.
- The dimensions represented by Not-Observable Nodes are excluded from this computation.
Deviance
- The Deviance measure is based on the difference between the Entropy of the to-be-evaluated network and the Entropy of the complete (i.e., fully-connected) network .
Definition
Deviance is formally defined as:
where
- is the Entropy of the dataset given the to-be-evaluated network .
- is the Entropy of the dataset given the complete (i.e., fully-connected) network .
- is the size of the dataset.
Using the values from the Data Table above, we obtain:
Interpretation
- The closer the Deviance value is to 0, the better the network represents the dataset.
Report Footer
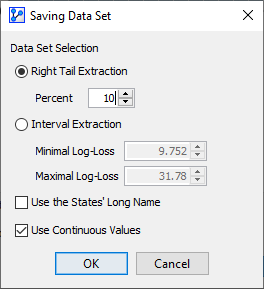
Extract Data Set
The final element in the report window is the Extract Data Set button. This is a practical tool for identifying and examining outliers, e.g., those at the far end of the right tail of the histogram.
-
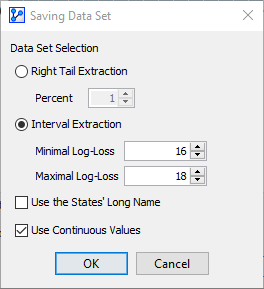
Clicking the Extract Data Set button brings up a new window that allows you to extract observations from the dataset according to the criteria you define:
-
Right Tail Extraction selects the specified percentage of observations, beginning with the highest Log-Loss value.
 Loading SVG...
Loading SVG... -
Interval Extraction allows you to specify a lower and upper boundary of Log-Loss values to be included.
 Loading SVG...
Loading SVG... -
Upon selecting either method and clicking OK, you are prompted to choose a file name and location.
-
BayesiaLab saves the observations that meet the criteria in CSV format.
-
Note that the Log-Loss values that are used for extraction are not included in the saved dataset.