Step 1 — Data Structure Definition: Text File
Context
-
Open Data Source (Data Import Wizard) brings data into BayesiaLab to create a new Bayesian network.
-
BayesiaLab can load data from flat text files (e.g., CSV, TXT) or connected databases.
Usage
- In Step 1 — Data Structure Definition: Text File of the five-step Data Import Wizard, you need to define the dataset structure for BayesiaLab so that the data can be imported and interpreted correctly.
- In Modeling Mode
F4, selectMain Menu > Data > Open Data Source > Text File. - The Data Structure Definition window opens.
- Specify all settings and options (see below).
- Click
Nextto proceed to Step 2 — Definition of Variable Types.
Elements in Step 1
Many of the settings can be immediately reviewed and validated in the Data Preview panel. However, Missing Values or Filtered Values can be mischaracterized and yet go unnoticed and, later, introduce major problems causing misleading analysis results.
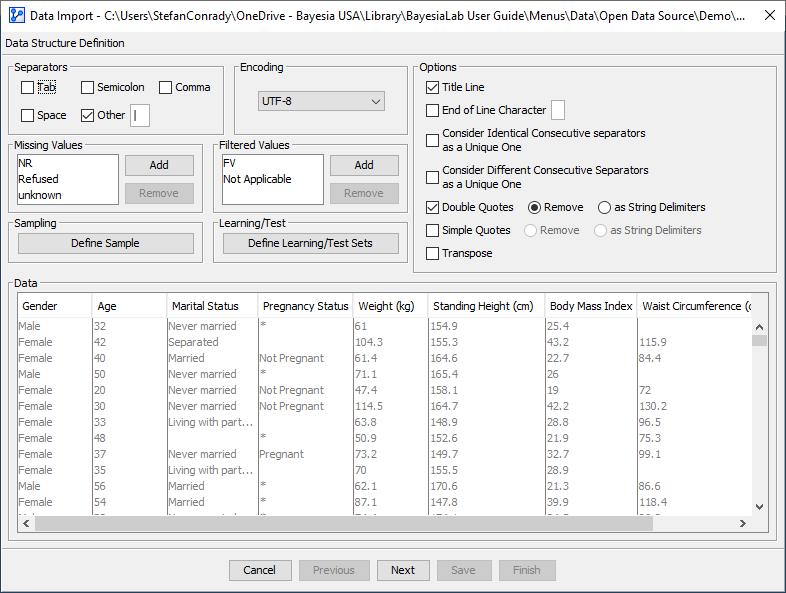
Separators
- The Data Import Wizard will attempt to automatically identify the separator or delimiter of the fields in the data table.
- However, there can be ambiguous situations in which you need to specify the separator by checking the appropriate box:
- Tab
- Semicolon
- Comma
- Space
- Other
If you prepare a dataset externally for import into BayesiaLab, ensure that separators are unique and do not appear as content in any data field. So, if any data fields contain text with commas as content, you cannot use commas as the separator. In such a case, try a tab or semicolon.
Encoding
-
The Encoding dropdown list allows you to select an alternative encoding for the dataset to be imported. This can become necessary for importing data from certain legacy systems.
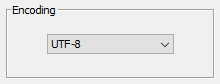
Missing Values
- Specifying the correct code for Missing Values is very important so that BayesiaLab can process such Missing Values appropriately.
- The list shows a number of codes that are commonly used for Missing Values. However, this is not necessarily comprehensive, and your dataset may contain different codes, such as ”.” (dot) or “-9999”, etc.
-
Click
Addto create a new entry in this list for the current data import. -
Clicking
Removedeletes the selected entries. -
Deleting a default entry such as NR (for no response) may become necessary, for instance, if a data field contains the string “NR” as a valid value. That would be the case if your dataset included New York Stock Exchange ticker symbols. In this context, “NR” would be the symbol of Newpark Resources, Inc. Unless you address this issue, all “NR” strings would be treated as Missing Values.
-
You can set your own default list of codes under
Main Menu > Window > Preferences > Data > Import & Associate > Missing & Filtered Values.
Filtered Values
-
Just as important as the correct definition of Missing Values is a clear understanding of a Filtered Value.
-
A Filtered Value occurs when a variable cannot have any value for logical reasons. For instance, in a demographic dataset, there could be a field Age at Retirement. However, in the record of a 16-year-old high school student in this dataset, there could be no value for the field Age at Retirement. However, this situation must not be treated as a Missing Value! A Missing Value implies that a value exists but is unknown. In the case of the student’s record, a value is logically impossible, not missing. So, instead of a numerical value or a blank, you must specify a code that says that there can be no value. This is the purpose of assigning a Filtered Value code.
-
Importantly, you must encode any Filtered Values before importing your dataset into BayesiaLab. In BayesiaLab, you merely need to declare what code you used in your dataset to represent Filtered Values. BayesiaLab will create a Filtered State as an additional state in each node for which Filtered Values are encountered during data import.

- Click
Addto create a new entry in this list for the current data import. - Clicking
Removedeletes the selected entries.
You can set your own default list of codes under Main Menu > Window > Preferences > Data > Import & Associate > Missing & Filtered Values.
- In Data Preview, all Filtered Values are marked with an asterisk (*) in the data table.
Understanding the difference between Missing Values and Filtered Values is critically important. For a detailed discussion of those concepts, please see Chapter 9: Missing Values Processing
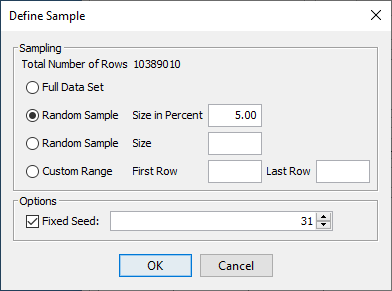
Sampling
-
Clicking the
Define Samplebutton opens a window that allows you to sample records from your data source. -
This is particularly useful for the preliminary analysis of large datasets. By default, BayesiaLab imports all records from the data.
-
You can define a subset in three ways:
- Random Sample — Size in Percent: specify the size of the random sample as a percentage of the original dataset size.
- Random Sample — Size: specify the number of records in the sampled dataset.
- Custom Range — First Row to Last Row: specify the range of records to be imported.
-
Checking the option
Fixed Seedand specifying a number ensures that you can repeat exactly the same random sampling for each iteration of the import. This allows you to reproduce your results as you develop your model.
Learning/Test
-
By default, the Data Import Wizard loads the entire dataset as a Learning Set.
-
By clicking the
Define Learning/Test Setsbutton, you can set aside a Test Set (or holdout sample). -
You can define the Learning Set/Test Set split in three ways:
- Random Test Set — Size in Percent: specify the size of the Test Set as a percentage of the original dataset size.
- Random Test Set — Size: specify the number of records in the Test Set.
- Custom Test Set — First Row to Last Row: select a specific range of records for a Test Set.
-
Checking the option Fixed Seed and specifying a number ensures that you can obtain the same Test Set with each iteration of the import. This allows you to reproduce your results and validation measures as you develop your model.
-
In addition to specifying a Learning Set/Test Set split here, you can define a split in other ways:
- You can designate a variable in the original dataset to assign records to the Learning Set and Test Set. You can select such a variable in the next step of the Data Import Wizard: Step 2 — Definition of Variable Types.
Main Menu > Data > Data Set > Generate Learning/Test Split- Right-click on the database icon in the Status Bar and select Generate Learning/Test Split.
-
Furthermore, you can remove the Learning Set/Test Set split at any time:
Main Menu > Data > Data Set > Remove Learning/Test Split.- Right-click on the database icon in the Status Bar and select Remove Learning/Test Split.
Options
- The Options Panel allows you to manage the interpretation of the dataset to be imported.
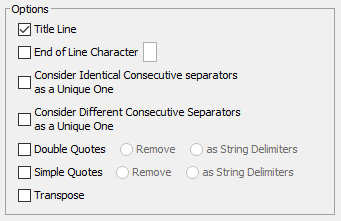
-
Title Line:
- By checking this option, BayesiaLab reads the first row of the dataset and uses its values as column headers.
- If the values in the first row are not compatible, e.g., due to missing values or duplicate values, you are prompted to accept the proposed corrections, which include adding suffixes for duplicate names and substituting missing values with generic column headers, e.g., N0, N1, N2, etc.
-
End of Line Character:
- With some files, it may be necessary to specify a certain character so that BayesiaLab can correctly detect the end of a row in a data table.
-
Consider Identical Consecutive Separators as One:
- Check this box so that if you have multiple consecutive separators of the same type, e.g., “;;;”, the Data Import Wizard will treat them as a single separator.
-
Consider Different Consecutive Separators as One:
- Check this box so that if you have multiple consecutive separators of any type, e.g., “;,|”, the Data Import Wizard will treat them as a single separator.
-
Double Quotes:
- Remove
- As String Delimiters
-
Simple Quotes:
- Remove
- As String Delimiters
-
Transpose:
- By default, BayesiaLab expects the data source to be arranged in
- columns corresponding to variables and
- rows corresponding to samples, records, or observations.
- Checking the Transpose option allows you to accept an alternate format, i.e.,
- rows corresponding to variables and
- columns corresponding to samples, records, or observations.
- The transposed format is commonly used in bioinformatics. For instance, variables representing genes — sometimes tens of thousands — are arranged row by row. Observations — sometimes only a few dozen — are placed in columns side by side.
- By default, BayesiaLab expects the data source to be arranged in
Data table
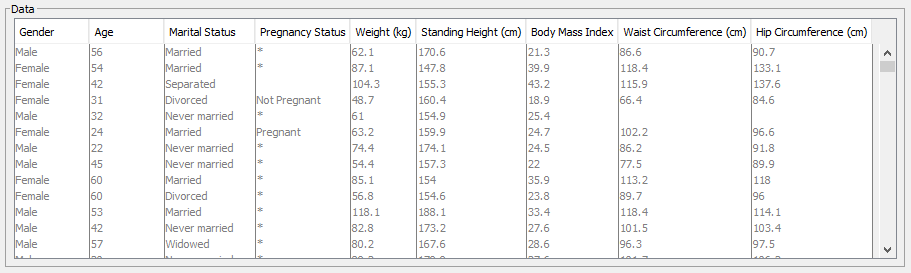
- The data table at the bottom of the window provides a preview of how the Data Import Wizard sees and interprets your dataset.
- Blank fields indicate a Missing Value.
- Asterisks (*) mark Filtered Values. In the dataset shown below, for instance, Filtered Values were assigned to all males and post-menopausal women for the variable Pregnancy Status. For those two groups and for obvious reasons, pregnancy is impossible.
- Horizontal and vertical sliders allow you to scroll and view the entire dataset. Alternatively, you can move your mouse’s scroll wheel up and down.
- If a variable name exceeds the column width, you can click on the divider between column headers and drag it into the desired position. Alternatively, double-click the divider to auto-fit the column width to the variable name.
Workflow Animation
In the following animation, we show a dataset that requires numerous settings to be adjusted for proper import:
- The dataset uses the pipe character (”|”) as a delimiter.
- All fields are enclosed in double quotes.
- Multiple, arbitrary codes are used for Missing Values:
- “Refused”
- “unknown”
- “Not Applicable” is the code for Filtered Value used in this dataset.
Note that there are no standardized codes for Missing Values and Filtered Values. They can be as arbitrary as in this example. Therefore, it is of utmost importance that whoever prepares the dataset must convey the precise meaning of these codes to the analyst who imports the data into BayesiaLab.