Data Clustering
Context
- Data Clustering is a type of unsupervised learning algorithm that creates a new node, .
- Each state of this newly-created node represents a Cluster. Loading SVG...
- Data Clustering can be used for different purposes:
- For finding observations that appear the same, i.e., have similar values.
- For finding observations that behave the same, i.e., interact similarly with other nodes in the network.
- For representing an unobserved dimension by means of an induced latent Factor.
- For summarizing a set of nodes.
- For compactly representing the Joint Probability Distribution.
- From a technical perspective, each cluster should be:
- Homogeneous and pure.
- Clearly differentiated from other clusters.
- Stable.
- From a functional perspective, all clusters should be:
- Easy to understand.
- Operational.
- A fair representation of the data.
- Data Clustering with Bayesian networks is typically based on a Naive Bayes structure, in which the newly-created latent Factor Node is the parent of the so-called Manifest Nodes.
- latent (adjective): (of a quality or state) existing but not yet developed or manifest; hidden or concealed.
- manifest (adjective): clear or obvious to the eye or mind.
-

- Because this variable is hidden (i.e., 100% missing values), the marginal probability distribution of and the conditional probability distributions of the Manifest variables are initialized with random distributions.
- Thus, an Expectation-Maximization (EM) algorithm is used to fit these distributions with the data:
- Expectation: the network is used with its current distributions to compute the posterior probabilities of for the entire set of observations described in the dataset. These probabilities are used for soft-imputing .
- Maximization: based on these imputations, the distributions of the network are updated via Maximum Likelihood. The algorithm goes back to Expectation until no significant changes occur to the distributions.
Usage
- You can either select a subset of nodes to be included in Data Clustering, or leave all nodes unselected. In the latter case, all nodes on the Graph Panel will be included for Data Clustering.
Feature History
Data Clustering has been updated in versions 5.1 and 5.2.
New Feature: Meta-Clustering
This new feature has been added to improve the stability of the induced solution (3rd technical quality). It consists of creating a dataset made from a subset of the Factors that have been created while searching for the best segmentation, and using Data Clustering on these new variables. The final solution is thus a summary of the best solutions that have been found (4th purpose).

The five Manifest variables (bottom of the graph) are used in the dataset for describing the observations.
The Factor variables , , and have been induced with Data Clustering. They are then imputed to create a new dataset.
In this example, three Factor variables are used for creating the final solution .
Example
Let’s use a dataset that contains house sale prices for King County , which includes the city of Seattle, Washington. It describes homes sold between May 2014 and May 2015. More specifically, we have extracted 94 houses that are more than 100 years old, that have been renovated, and come with a basement. For simplicity, we are just describing the houses with the 5 Manifest variables below, discretized into 2 bins.
- : Overall grade given to the housing unit
- : Square footage of house, apart from basement
- : Living room area in 2015
- : Square footage of the lot
- : Latitude coordinate
The wizard below shows the settings used for segmenting these houses:
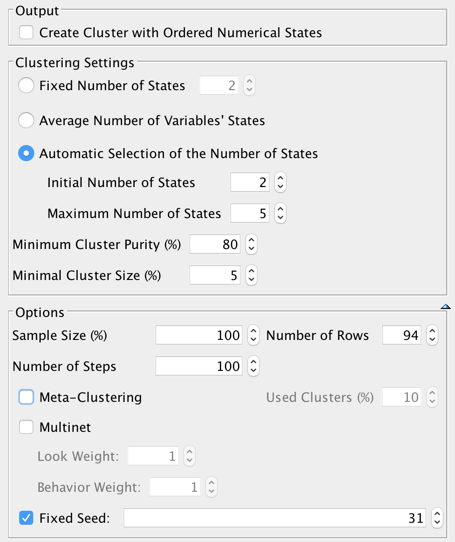
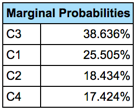
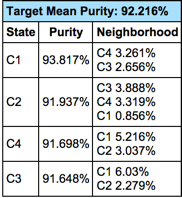
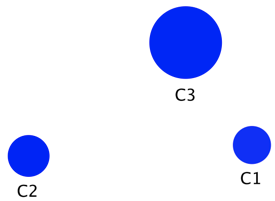
After 100 steps, segmenting the houses into four groups is the best solution. Below, the Mapping function shows the newly created states/segments:
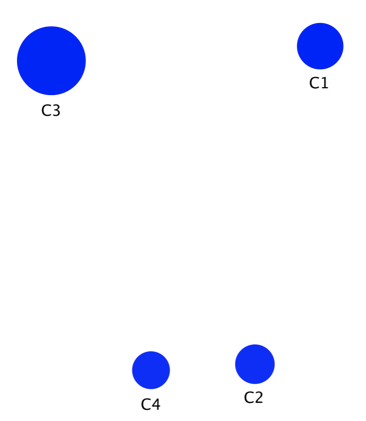
- The size of each segment is proportional to its marginal probability (i.e., how many houses belong to each segment),
- the intensity of the blue is proportional to the purity of the associated cluster (1st technical quality), and
- the layout reflects the neighborhood.
This radar chart (Main Menu > Analysis > Report > Target > Posterior Mean Analysis > Radar Chart) allows interpreting the generated segments. As we can see, they are easily distinguishable (2nd technical quality).

Thus, the solution with 4 segments satisfies the first two technical qualities listed above. However, what about the 3rd one, the stability? Below are the scores of the 10 best solutions that have been generated while learning:
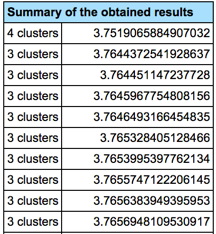
Even though the best solution is made of 4 segments, this is the only solution with 4 clusters, all the other ones have nearly the same score, but with 3 clusters. Thus, we can assume that a solution with 3 clusters would be more stable.
Using Meta-Clustering on the 10 best solutions (10%) indeed generates a final solution made of 3 clusters.

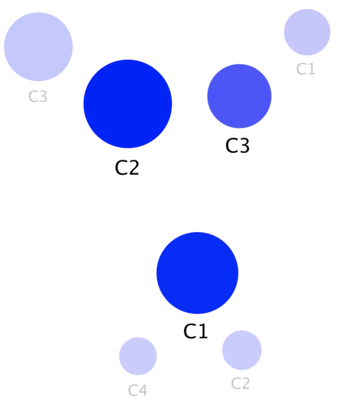
This mapping juxtaposes the mapping of the initial solution with 4 segments (lower opacity) and the one corresponding to the meta-clustering solution.
The relationships between the final and initial segments are as follows:
- groups and (the main difference between and was Square footage of the lot),
- corresponds to
- corresponds to

New Feature: Multinet
As stated in the Context, Data Clustering with Bayesian networks is typically done with Expectation-Maximization (EM) on a Naive structure. Thus, it is based on the hypothesis that the Manifest variables are conditionally independent of each other given . Therefore, the Naive structure is well suited for finding observations that look the same (1st purpose), but not so good for finding observations that behave similarly (2nd purpose). The behavior should be represented by direct relationships between the Manifest variables.
Our new Multinet clustering is an EM2 algorithm based both on a Naive structure (Look) and on a set of Maximum Weight Spanning Trees (MWST) (Behavior). Once the distributions of the Naive are randomly set, the algorithm works as follows:
- Expectation_Naive: the Naive network is used with its current distributions for computing the posterior probabilities of , for the entire set of observations described in the dataset. These probabilities are used for hard-imputing , i.e., choosing the state with the highest posterior probability;
- Maximization_MWST: is used as a breakout variable. An MWST is learned on each subset of data.
- Expectation_MWST: the joint probabilities of the observations are computed with each MWST and used for updating the imputation of .
- Maximization_Naive: based on this updated imputation, the distributions of the Naive network are updated via Maximum-Likelihood. Then, the algorithm goes back to Expectation_Naive until no significant changes occur to the distributions.
Two parameters allow changing the Look/Behavior equilibrium. They can be considered as probabilities to run the Naive and MWST steps at each iteration.
Setting a weight of 0 for Behavior defines a Data Clustering quite similar to the usual one (EM), but based on hard imputation instead of soft imputation.
Example
Let’s use the same dataset that describes houses in Seattle.
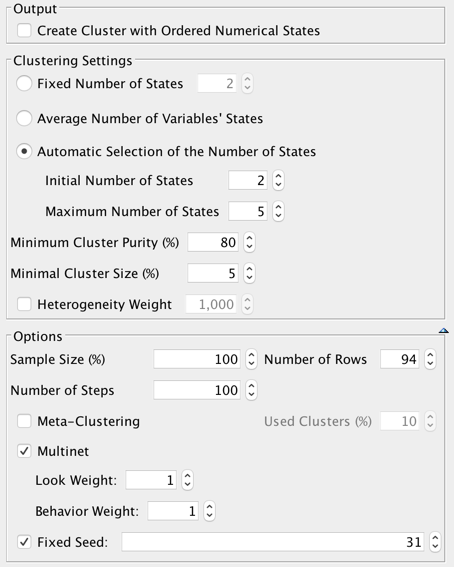
The wizard below shows the settings we used for segmenting the houses:
After 100 steps, segmenting the houses into three groups is the best solution. The final network is a Naive Augmented Network, with a direct link between two Manifest variables, which are, therefore, not independent given the segmentation, i.e. the Behavior part. Note that this dependency is valid for only, which can be seen after performing inference with the network.

The radar chart allows analyzing the Look of the segments.

New Feature: Heterogeneity Weight
The assumption that the data is homogeneous, given all the Manifest Variables, can sometimes be unrealistic. There may be significant heterogeneity in the data across unobserved groups, and it can bias the machine-learned Bayesian networks. This phenomenon is known as Unobserved Heterogeneity, i.e. an unobserved variable in the dataset.
Data Clustering represents a solution for searching for such hidden unobserved groups (3rd purpose). However, whereas the default scoring function in Data Clustering is based on the entropy of the data, finding heterogeneous groups requires modifying the scoring function.
We thus defined a Heterogeneity Index :
,
with
where:
- is the induced Factor,
- are the states of the Factor, i.e. the segments used to split the data,
- is the marginal probability of state , i.e. the relative size of the segment,
- is the set of Manifest variables,
- is the entire dataset,
- is the subset of the data that corresponds to the segment
- is the Mutual Information between a Manifest variable and the Target Node , computed on the dataset .
The Heterogeneity Weight allows setting a weight of the Heterogeneity Index in the score, which will, therefore, bias the selection of the solutions toward segmentations that maximize the Mutual Information of the Manifest variables with the Target Node.
Example
Let’s use the entire dataset that describes houses in Seattle, with this subset of Manifest variables:
- : indicates if the house has been renovated
- : Age of the house
- : Living room area in 2015
- : Longitude coordinate
- : Latitude coordinate
- : Price of the house.
After setting as a Target Node and selecting all the other variables, we use the following settings for Data Clustering:
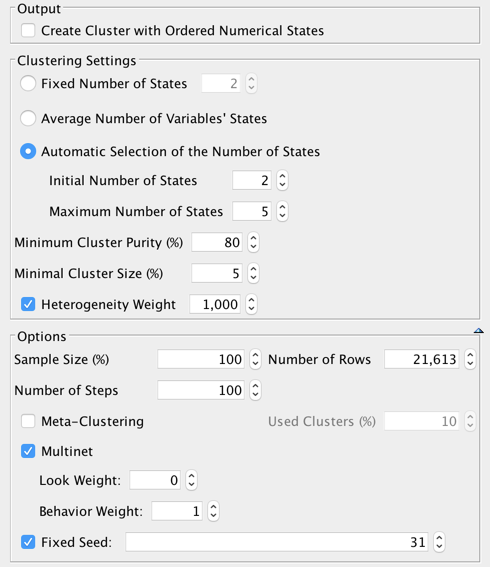
This returns a solution with 2 segments, generating a Heterogeneity Index of 60%. This indicates, therefore, that using as a breakout variable would increase the sum of the Mutual Information of the Manifest variables with the Target Node by 60%.
The Quadrant Chart below highlights the improvement of the Mutual Information. The points correspond to the Mutual Information values on the entire dataset, and the vertical scales show the variations in Mutual Information by splitting the data based on the values of .
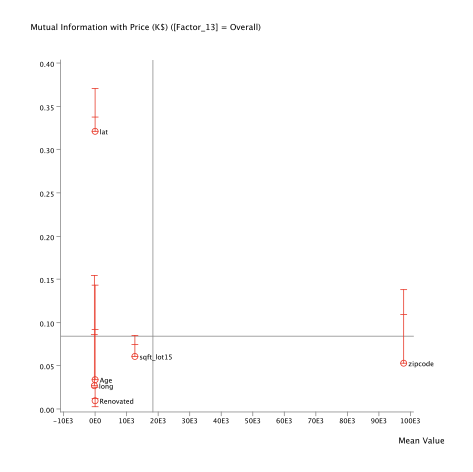
The Heterogeneity Index is computed on the Manifest variables that are used during the segmentation only. To take other variables into account in the computation of the index, these variables have to be included in the segmentation with a weight of 0 to prevent them from influencing the segmentation.
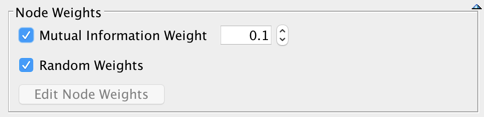
New Feature: Random Weights
By default, the weight associated with a variable is set to 1. Whereas a weight of 0 renders the variable purely illustrative, a weight of 2 is equivalent to duplicating the variable in the dataset. The option Mutual Information Weight, introduced in version 5.1, allows weighting the variable by taking into account its Mutual Information with the Target node.
As of version 7.0, a new option, Random Weights, allows you to modify the weight values randomly while trying to find the best segmentation. The amplitude of the randomness is inversely proportional to the current number of trials, therefore starting with the maximum level of randomness and ending with almost no weight modification. This option can be useful for escaping local minima.