Batch Labeling — Posterior Probabilities
Context
- Batch Labeling is used for processing the set of observations described in a dataset or an associated Evidence Scenario File.
- The multidimensional observations are defined by the values of the nodes that are observable and not missing.
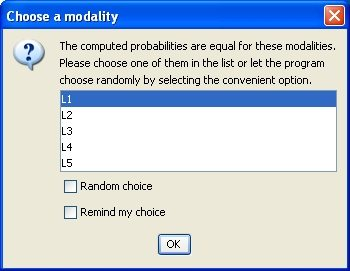
- The values of the Target Node and the Not Observable nodes are not used to define the set of evidence, even when there is a corresponding value in the dataset row or Evidence Scenario File. Each observation is then iteratively set as evidence in the network, and the posterior probability distributions of the Target Node and/or of the Not Observable variables are updated accordingly. Thus, by default, the state with the highest posterior probability is chosen for the imputation. However, for binary nodes, a dialog box lets you set the probability acceptance threshold. If the posterior distribution is uniform, a dialog box lets you define the imputation policy:
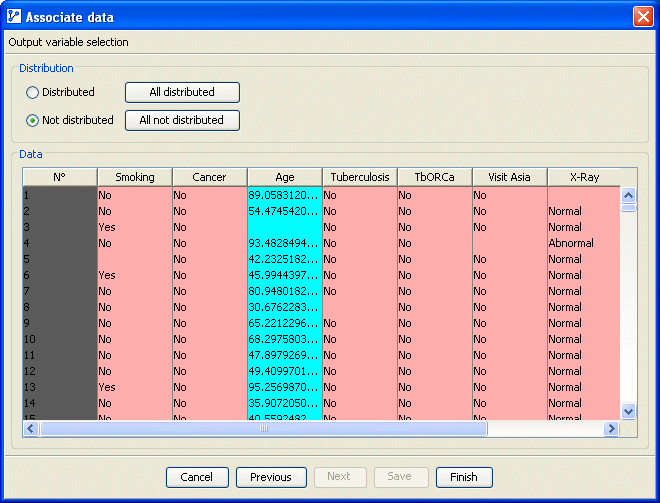
The imputations are stored in an output file that takes the selected fields of the input file and creates two additional fields per imputed variable: one for the imputed value, the other for the posterior probability used for the decision. If the data source is an external database, the fields of the input file that are included in the exploitation file are selected via the wizard illustrated below:
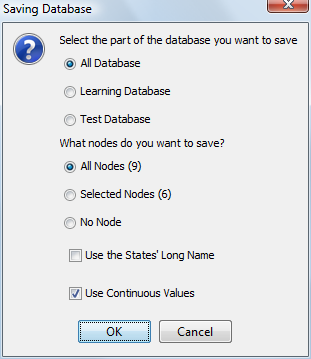
If the data source is the associated database, a dialog allows the user to choose which part of the dataset (all, learning, or test) will be processed and which nodes will be saved in the output file. It is also possible to choose whether the states’ long names are used and whether the continuous values are saved: