Maximum Likelihood Estimation with Priors
Context
- BayesiaLab can also take into account Priors when estimating parameters using Maximum Likelihood Estimation.
- Priors reflect any a priori knowledge of an analyst regarding the domain, in other words, expert knowledge. See also Prior Knowledge for Structural Learning.
- These priors are expressed with an analyst-specified, initial Bayesian network (structure and parameters) plus analyst-specified Prior Samples.
- Prior Samples represent the analyst’s subjective degree of confidence in the Priors.
where
- is the degree of confidence in the Prior.
- is the joint probability returned by the prior Bayesian network.
- BayesiaLab uses these two terms to generate virtual samples that are subsequently combined with the observed samples from the dataset.
Virtual Database Generator
- With your current Bayesian network, you can generate Priors
- Select
Menu > Data > Prior Samples > Generate. - You can specify by setting the number of Prior Samples.
-
BayesiaLab uses the current Bayesian network to compute .
-
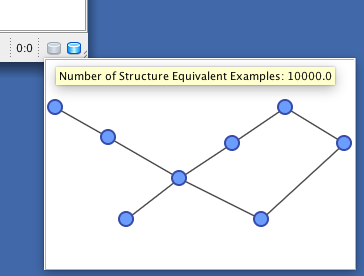
The existence of a new Virtual Database is indicated by an icon in the lower right corner of the graph window, next to the “real dataset” icon .
-
Right-clicking on the Virtual Database icon displays the structure of the prior knowledge that was used for generating the Virtual Samples.
-
These Virtual Samples will be combined with the observed “real” samples during the learning process.
Number of Uniform Prior Samples
-
Edit Number of Uniform Prior Samples allows you to define prior knowledge in such a way that all the variables are marginally independent (fully unconnected network), and the marginal probability distributions of all nodes are uniform.
-
For instance, if the number of Prior Samples is set to 1, one observation (“occurrence”) would be “spread across” all states of each node, essentially assigning a “fraction of an observation” to each node’s states.
-
To apply Smoothed Probability Estimation, select
Menu > Edit > Edit Smoothed Probability Estimation -
Specify the number of Prior Samples.